Much thanks for your time and expertise Gang.
Yes, I agree with your assessment of the situation, in terms of A-C and B-C being larger than A-B. I question, though, whether A-C and B-C differ so little, perhaps more than the .9% and .8% that you suggest. Given the substantial differences between A and B in the number of voxels that they activate above the active baseline (C), it might well be the case that the difference between these effects is quite a bit larger.
Another thing that I might disagree with is your phrase “artificially dichotomizing the evidence” in the sentence, “furthermore, you do see a bigger cluster for effect A than B, relative to C, when artificially dichotomizing the evidence with a preset threshold.” I’m not sure what you mean by this. When we assess A and B relative to C, we create condition maps for A and B within 3dLME in exactly the same as we would when computing A-B contrasts. We’re not doing anything different at all up to this point. The process is exactly the same for both. The only difference is that we take the maps that 3dLME produces for A-C and B-C and export them to a conjunction analysis in 3dcalc instead of contrasting the A-C and B-C maps with a GLT in 3dLME.
I tried what you suggested for the A-B contrast, lowering the p threshold to .1 and dropping FWE correction. Bits and pieces of various effects emerge in the ROIs, but things are still relatively weak and scattered, especially in key areas such as the insula, OFC, and amygdala. I do agree with your general point, though, that signal change for A-B is much less than for A-C and for B-C.
My main concern is that assessing signal change for A-B may be asking the wrong question. I totally get your point about the conventional comfort zone, but I increasingly wonder whether staying in this comfort zone is causing us to miss all sorts of important information about what’s happening in our experiments. I hasten to add that I’m not trying to defend weak effects. I’m totally on board with powering experiments appropriately, replicating effects, and ensuring that they’re real. I don’t want to be part of the problem of producing unreplicable effects. At the same, I want to measure things accurately, and I increasingly believe that linear contrasts like A-B here may not be doing so.
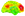
One problem that I have with A-B intensity contrasts is that they don’t tell us what becomes active for a task above baseline. They just tell us how two conditions for the same task differ from each other. When one uses a well-matched active baseline, the A-C and B-C contrasts become increasingly informative. Relative to a reference set of processes, we establish the brain areas that a task engages throughout the brain. When we look at the areas that emerged from our A-C and B-C contrasts, we see all the areas that the task engaged, above a well-designed reference task. I’ve attached two figures here for the kinds of results we see. There are two more figures that I can’t attach (because only two are allowed) that show still other interesting areas that our task engages. If we looked at A-B signal change contrasts in the same areas, we’d see very little in the way of activations, thereby not having a sense of the brain areas that the task engages. So this is one reason why I have a problem with the conventional comfort zone.
The other is that when conventional methods assess signal strength for A-B, they may be missing important differences that aren’t false positives but that are real effects. I increasingly believe that breadth of activation may be a more sensitive measure of differences between A and B than differences in activation intensity. I increasingly wonder why we believe that intensity of activation is a more informative and more accurate measure of processing than breadth of activation. Perhaps differences in breadth reflect greater differences in what’s being computed cognitively than differences in intensity.
One piece of evidence for this is that when we compute the voxel counts for individual participants (measuring activation breadth) and submit them to mixed-effects modeling in R (using lmer), we find large significant effects across participants (as random effects). So far, we have only done this at the whole brain level, not at the ROI level. When we do it at the whole brain level, however, we find large significant effects across participants. For example, tasty foods activate more voxels than healthy foods, robustly across the brain. Even though we don’t see evidence for this in A-B intensity contrasts in the group activation map, we see large effects from breadth analyses in A-C and B-C individual maps. You can see this overall effect in the first image of a voxel count table in my previous post. You can also see this overall effect in the two images attached to this post. There are even larger effects of contrasting individual voxel counts when comparing activation breadth for the normal viewing versus observe manipulation, which again doesn’t show up much in the A-B contrast intensity maps. Again, my point is that assessing activation breadth using voxel counts may be a more sensitive measure of how two conditions differ than contrasting their differences in intensity.
I realize that there may be no good ways to assess the statistical significance of breadth differences in the group level maps (as I asked in my original post). Perhaps the best approach is to pull out voxel counts from individual participants and then test them externally in lmer analyses, as just described above. We could easily do this at the ROI level, as well as for the whole brain.
One other thought is that it might be informative to create simulated data sets that vary systematically in signal strength and activation breadth, and then look at the implications for various kinds of tests, including A-B intensity contrasts and contrasts between A-C and B-C breadth. It would be interesting to see if breadth is indeed a more sensitive measure of detecting effects between A and B when false discovery rates are well controlled. If so, this might suggest considering an additional way to define our comfort zone.
Again, thank you so much for your help and expertise. We’re most grateful. We look forward to hearing any further thoughts and suggestions that you have.
Warm regards, Larry



{kind=link}
{kind=link}
{kind=link}
{kind=link}