9.8. Notes on 3dREMLfit¶
Notes by RW Cox.
9.8.1. Background: time series censoring approaches¶
A question came up:
Is the way AFNI’s time series regression programs, 3dREMLfit and 3dDeconvolve, deal with time point censoring equivalent to the way that other programs (e.g., SPM, FSL) deal with such censoring?
To understand the alternatives, consider the regression model for a
single time series data vector  with N time points
and M regressor (model) component:
with N time points
and M regressor (model) component:

where  is an
is an  matrix,
matrix,  is an M-vector, and is the N-vector of residuals
(to be made as “small” as possible when solving for
). Suppose that element
is an M-vector, and is the N-vector of residuals
(to be made as “small” as possible when solving for
). Suppose that element  is to be
censored out of the analysis for whatever silly reason (e.g., too much
head motion).
is to be
censored out of the analysis for whatever silly reason (e.g., too much
head motion).
Row removal (AFNI approach): Remove the ith element from
and correspondingly remove the ith row from the
matrix (since it is that row which contains the
model for ).Column augmentation (SPM and FSL approach): Add a column to
that is all zero except for a single 1 in the ith
element. The idea is that this extra regression component will
exactly fit the data point in and so the
value for this extra component will be
, and all the other components of beta will be
devoted to fitting the “real” data in the rest of vector
. One column is added for each index i which is
to be censored.
The advantages of the row removal method are (a) that it shrinks the
matrix, reducing the computational load, and (b)
that it exactly accounts for the non-use of since
the offending value is omitted entirely from the analysis. The
disadvantage of the row removal method is that it breaks the regular
time spacing of the data. The column augmentation method has the
inverse characteristics.
9.8.2. Are the censoring approaches the same for 3dREMLfit?¶
If some non-AFNI pipeline wants to use 3dREMLfit, the developers
are likely to want to censor using the column augmentation method,
since that is what most neuroscience people are familiar with. The
question arose in my mind about whether the two approaches give the
same results in 3dREMLfit.
Regular time spacing is not important if ordinary least squares (OLSQ)
is used to fit . However, if a temporal correlation
matrix  needs to be estimated from the data, and
then applied to “pre-whiten” the problem, then the temporal spacing
needs to be properly allowed for when model-fitting
and together. Some algorithms for fitting models for R
are much simpler with regular (unbroken
needs to be estimated from the data, and
then applied to “pre-whiten” the problem, then the temporal spacing
needs to be properly allowed for when model-fitting
and together. Some algorithms for fitting models for R
are much simpler with regular (unbroken  ) time
spacing; for example, the Yule-Walker equations for AR(p) models, or
even more obviously, DFT-based approaches. AFNI’s 3dREMLfit was built
to avoid the requirement for a regular TR, by using a voxelwise
ARMA(1,1) model - see 3dREMLfit_mathnotes (RWC’s math notes on
3dREMLfit)
for the details. Non-contiguous segments of data (“runs”) can be
catenated and analyzed together, as well as allowing for censoring
time points where bad things happened. The voxelwise computation of
the ARMA(1,1) autocorrelation prewhitening model is meant to allow
for different types of temporal correlation structure in different
image regions and tissue types. (Is this useful? Opinions vary.)
) time
spacing; for example, the Yule-Walker equations for AR(p) models, or
even more obviously, DFT-based approaches. AFNI’s 3dREMLfit was built
to avoid the requirement for a regular TR, by using a voxelwise
ARMA(1,1) model - see 3dREMLfit_mathnotes (RWC’s math notes on
3dREMLfit)
for the details. Non-contiguous segments of data (“runs”) can be
catenated and analyzed together, as well as allowing for censoring
time points where bad things happened. The voxelwise computation of
the ARMA(1,1) autocorrelation prewhitening model is meant to allow
for different types of temporal correlation structure in different
image regions and tissue types. (Is this useful? Opinions vary.)
Aside – Solution methods:
The OLSQ solution is ![\beta = [\mathbf{X}^T\mathbf{X}]^{-1}
\mathbf{X}^T \mathbf{z}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuMi4xIC0tPgo8c3ZnIHZlcnNpb249JzEuMScgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluaycgd2lkdGg9Jzk4LjYyMjIzM3B0JyBoZWlnaHQ9JzE1LjQ4NzkyNXB0JyB2aWV3Qm94PSc1Ni43NDY3NjEgNTMuNzUyMDE1IDk4LjYyMjIzMyAxNS40ODc5MjUnPgo8ZGVmcz4KPHVzZSBpZD0nZzE3LTQ5JyB4bGluazpocmVmPScjZzUtNDknLz4KPHBhdGggaWQ9J2c1LTQ5JyBkPSdNMi45OTIyOTgtNi45NTExOEwxLjE0MTM5Mi02LjAxNTQ0NVYtNS44NzE0ODVDMS4yNjQ3ODYtNS45MjI4OTkgMS4zNzc4OTctNS45NjQwMzEgMS40MTkwMjgtNS45ODQ1OTZDMS42MDQxMTktNi4wNTY1NzYgMS43Nzg5MjYtNi4wOTc3MDcgMS44ODE3NTQtNi4wOTc3MDdDMi4wOTc2OTMtNi4wOTc3MDcgMi4xOTAyMzktNS45NDM0NjUgMi4xOTAyMzktNS42MTQ0MTVWLS45NTYzMDFDMi4xOTAyMzktLjYxNjk2OSAyLjEwNzk3Ni0uMzgwNDY0IDEuOTQzNDUxLS4yODc5MTlDMS43ODkyMDktLjE5NTM3MyAxLjY0NTI1LS4xNjQ1MjUgMS4yMTMzNzItLjE1NDI0MlYwSDQuMDUxNDI4Vi0uMTU0MjQyQzMuMjM5MDg2LS4xNjQ1MjUgMy4wNzQ1NjEtLjI2NzM1MyAzLjA3NDU2MS0uNzYwOTI4Vi02LjkzMDYxNUwyLjk5MjI5OC02Ljk1MTE4WicvPgo8cGF0aCBpZD0nZzMtMCcgZD0nTTYuNzc2MzczLTIuMzY1MDQ3QzYuOTUxMTgtMi4zNjUwNDcgNy4xMzYyNzEtMi4zNjUwNDcgNy4xMzYyNzEtMi41NzA3MDNTNi45NTExOC0yLjc3NjM1OSA2Ljc3NjM3My0yLjc3NjM1OUgxLjIxMzM3MkMxLjAzODU2NC0yLjc3NjM1OSAuODUzNDczLTIuNzc2MzU5IC44NTM0NzMtMi41NzA3MDNTMS4wMzg1NjQtMi4zNjUwNDcgMS4yMTMzNzItMi4zNjUwNDdINi43NzYzNzNaJy8+CjxwYXRoIGlkPSdnMTAtODQnIGQ9J002LjUwOTAyLTYuNzE0Njc2SDEuMDM4NTY0TC42MDY2ODYtNS4xMzExMjNMLjc5MTc3Ni01LjA4OTk5MkMxLjMzNjc2NS02LjIwMDUzNSAxLjY2NTgxNS02LjM3NTM0MyAzLjIzOTA4Ni02LjM1NDc3N0wxLjc1ODM2MS0uOTI1NDUzQzEuNTkzODM2LS4zODA0NjQgMS4zNDcwNDgtLjIxNTkzOSAuNjY4MzgzLS4xNjQ1MjVWMEgzLjY1MDM5OFYtLjE2NDUyNUMzLjQ3NTU5LS4xNzQ4MDggMy4zMjEzNDgtLjE5NTM3MyAzLjI1OTY1MS0uMTk1MzczQzIuODQ4MzM5LS4yMjYyMjIgMi43MjQ5NDUtLjMxODc2NyAyLjcyNDk0NS0uNjI3MjUxQzIuNzI0OTQ1LS43NjA5MjggMi43NTU3OTMtLjg4NDMyMiAyLjg0ODMzOS0xLjIzMzkzN0w0LjI3NzY0OS02LjM1NDc3N0g0Ljg0MzIwNEM1LjU4MzU2Ni02LjM1NDc3NyA1LjkxMjYxNi02LjA5NzcwNyA1LjkxMjYxNi01LjUyMTg3QzUuOTEyNjE2LTUuMzg4MTkzIDUuOTAyMzM0LTUuMjMzOTUxIDUuODgxNzY4LTUuMDU5MTQzTDYuMDU2NTc2LTUuMDM4NTc3TDYuNTA5MDItNi43MTQ2NzZaJy8+CjxwYXRoIGlkPSdnMS04OCcgZD0nTTkuNTYwMTY0LTkuMzkzNDE3SDYuMDg2MjY3Vi05LjA0NjAyOEM2LjIxMTMyOC05LjAzMjEzMiA2LjMyMjQ5Mi05LjAzMjEzMiA2LjM2NDE3OS05LjAxODIzNkM2LjkyMDAwMy04Ljk5MDQ0NSA3LjA4Njc1LTguODY1Mzg1IDcuMDg2NzUtOC41MzE4OTFDNy4wODY3NS04LjI0MDA4MyA2LjkzMzg5OC03Ljk0ODI3NiA2LjI4MDgwNi03LjA1ODk1OUM2LjE2OTY0MS02LjkyMDAwMyA1Ljg1MDA0Mi02LjQ3NTM0NCA1LjUwMjY1My01Ljk4ODk5OEw0LjE1NDc4MS04LjA3MzMzNkMzLjk3NDEzOC04LjM1MTI0OCAzLjk0NjM0Ny04LjQyMDcyNiAzLjk0NjM0Ny04LjU4NzQ3M0MzLjk0NjM0Ny04Ljg3OTI4MSA0LjExMzA5NC04Ljk5MDQ0NSA0LjYxMzMzNS05LjAxODIzNkM0LjY4MjgxMy05LjAxODIzNiA0Ljg0OTU2LTkuMDMyMTMyIDUuMDQ0MDk4LTkuMDQ2MDI4Vi05LjM5MzQxN0guMjM2MjI1Vi05LjA0NjAyOEMuNzM2NDY2LTkuMDA0MzQxIC45MTcxMDktOC44NjUzODUgMS4zNDc4NzItOC4yNDAwODNMNC4wOTkxOTgtNC4xOTY0NjdMMS42Njc0NzEtMS4xMjU1NDNDMS4yNTA2MDMtLjYxMTQwNiAuOTE3MTA5LS40MzA3NjMgLjIyMjMyOS0uMzQ3MzlWMEgzLjY5NjIyNlYtLjM0NzM5QzIuODQ4NTk1LS40MzA3NjMgMi41NzA2ODQtLjU2OTcxOSAyLjU3MDY4NC0uOTE3MTA5QzIuNTcwNjg0LTEuMjIyODEyIDIuODQ4NTk1LTEuNjY3NDcxIDMuODc2ODY5LTMuMDU3MDI5TDQuNDA0OTAxLTMuNzY1NzA0TDUuODA4MzU2LTEuNTE0NjE5QzUuOTc1MTAzLTEuMjUwNjAzIDYuMTAwMTYzLS45MTcxMDkgNi4xMDAxNjMtLjc2NDI1N0M2LjEwMDE2My0uNTI4MDMyIDUuODYzOTM4LS40MDI5NzIgNS4zNzc1OTItLjM3NTE4MUM1LjMyMjAxLS4zNzUxODEgNS4xNjkxNTktLjM2MTI4NSA0Ljk4ODUxNi0uMzQ3MzlWMEg5LjcxMzAxNlYtLjM0NzM5QzkuMjQwNTY2LS4zNjEyODUgOS4wMzIxMzItLjU0MTkyOCA4LjM2NTE0NC0xLjU0MjQxTDUuODM2MTQ3LTUuNDc0ODYyTDYuOTQ3Nzk0LTcuMDE3MjcyQzguMTcwNjA2LTguNjg0NzQyIDguNTMxODkxLTguOTQ4NzU4IDkuNTYwMTY0LTkuMDQ2MDI4Vi05LjM5MzQxN1onLz4KPHBhdGggaWQ9J2cxLTEyMicgZD0nTTUuODM2MTQ3LTIuMjIzMjk0SDUuNDQ3MDdDNS4zMjIwMS0xLjc3ODYzNSA1LjIxMDg0NS0xLjUyODUxNSA0Ljk4ODUxNi0xLjIzNjcwN0M0LjU0Mzg1Ny0uNjI1MzAxIDQuMDg1MzAzLS40NDQ2NTkgMi45NzM2NTYtLjQ0NDY1OUgyLjU3MDY4NEw1Ljc4MDU2NC02LjA0NDU4MVYtNi40MDU4NjZILjYyNTMwMUwuNTI4MDMyLTQuNDMyNjkySC44ODkzMThDMS4yMzY3MDctNS43NTI3NzMgMS41OTc5OTMtNS45NzUxMDMgMy41NDMzNzUtNS45NjEyMDdMLjI5MTgwNy0uMzQ3MzlWMEg1LjYxMzgxN0w1LjgzNjE0Ny0yLjIyMzI5NFonLz4KPHVzZSBpZD0nZzIyLTYxJyB4bGluazpocmVmPScjZzE4LTYxJyB0cmFuc2Zvcm09J3NjYWxlKDEuMzUxMzQxKScvPgo8dXNlIGlkPSdnMjItOTEnIHhsaW5rOmhyZWY9JyNnMTgtOTEnIHRyYW5zZm9ybT0nc2NhbGUoMS4zNTEzNDEpJy8+Cjx1c2UgaWQ9J2cyMi05MycgeGxpbms6aHJlZj0nI2cxOC05MycgdHJhbnNmb3JtPSdzY2FsZSgxLjM1MTM0MSknLz4KPHVzZSBpZD0nZzEyLTk4JyB4bGluazpocmVmPScjZzgtOTgnIHRyYW5zZm9ybT0nc2NhbGUoMS4zNTEzNDEpJy8+CjxwYXRoIGlkPSdnMTgtNjEnIGQ9J003LjA2NDI5MS0zLjM2MjQ3OUM3LjIxODUzMy0zLjM2MjQ3OSA3LjQxMzkwNy0zLjM2MjQ3OSA3LjQxMzkwNy0zLjU2ODEzNVM3LjIxODUzMy0zLjc3Mzc5MiA3LjA3NDU3NC0zLjc3Mzc5MkguOTE1MTdDLjc3MTIxMS0zLjc3Mzc5MiAuNTc1ODM3LTMuNzczNzkyIC41NzU4MzctMy41NjgxMzVTLjc3MTIxMS0zLjM2MjQ3OSAuOTI1NDUzLTMuMzYyNDc5SDcuMDY0MjkxWk03LjA3NDU3NC0xLjM2NzYxNEM3LjIxODUzMy0xLjM2NzYxNCA3LjQxMzkwNy0xLjM2NzYxNCA3LjQxMzkwNy0xLjU3MzI3UzcuMjE4NTMzLTEuNzc4OTI2IDcuMDY0MjkxLTEuNzc4OTI2SC45MjU0NTNDLjc3MTIxMS0xLjc3ODkyNiAuNTc1ODM3LTEuNzc4OTI2IC41NzU4MzctMS41NzMyN1MuNzcxMjExLTEuMzY3NjE0IC45MTUxNy0xLjM2NzYxNEg3LjA3NDU3NFonLz4KPHBhdGggaWQ9J2cxOC05MScgZD0nTTIuNjIyMTE3IDIuNTcwNzAzVjIuMTU5MzlIMS42MjQ2ODRWLTcuMzAwNzk2SDIuNjIyMTE3Vi03LjcxMjEwOEgxLjIxMzM3MlYyLjU3MDcwM0gyLjYyMjExN1onLz4KPHBhdGggaWQ9J2cxOC05MycgZD0nTTEuNjM0OTY3LTcuNzEyMTA4SC4yMjYyMjJWLTcuMzAwNzk2SDEuMjIzNjU1VjIuMTU5MzlILjIyNjIyMlYyLjU3MDcwM0gxLjYzNDk2N1YtNy43MTIxMDhaJy8+CjxwYXRoIGlkPSdnOC05OCcgZD0nTS43MDk1MTQgLjYzNzUzNEMuNjE2OTY5IDEuMTgyNTIzIC40MTEzMTIgMS44OTIwMzcgLjI0Njc4NyAyLjI4Mjc4NEgxLjA4OTk3OEMxLjI2NDc4NiAyLjA0NjI3OSAxLjMzNjc2NSAxLjc2ODY0NCAxLjQ3MDQ0MiAuOTY2NTg0TDEuNzA2OTQ3LS40MzE4NzhDMi4xNzk5NTYtLjAyMDU2NiAyLjYxMTgzNCAuMTMzNjc3IDMuMjA4MjM3IC4xMzM2NzdDNC40MzE4OTIgLjEzMzY3NyA1LjQyOTMyNC0uNzcxMjExIDUuNjQ1MjYzLTIuMDk3NjkzQzUuODMwMzU0LTMuMTk3OTU0IDUuNDA4NzU5LTMuOTY5MTY1IDQuMzU5OTEyLTQuNDUyNDU3QzUuMjEzMzg1LTQuODc0MDUzIDUuNjY1ODI5LTUuMzQ3MDYyIDUuNzU4Mzc0LTUuOTMzMTgyQzUuOTEyNjE2LTYuODQ4MzUyIDUuMTMxMTIzLTcuNjA5MjggNC4wMzA4NjItNy42MDkyOEMyLjkyMDMxOC03LjYwOTI4IDEuOTY0MDE3LTYuODc5MjAxIDEuNzk5NDkyLTUuOTAyMzM0TC43MDk1MTQgLjYzNzUzNFpNMi42NDI2ODItNi4wMDUxNjJDMi43NTU3OTMtNi43MjQ5NTkgMy4yNjk5MzQtNy4yMjg4MTYgMy44NzY2Mi03LjIyODgxNkM0LjUyNDQzNy03LjIyODgxNiA0Ljg5NDYxOC02LjYzMjQxMyA0Ljc1MDY1OS01LjgwOTc4OEM0LjY2ODM5Ni01LjI2NDc5OSA0LjI3NzY0OS00LjY3ODY3OSA0LjAxMDI5Ni00LjY3ODY3OUMzLjk3OTQ0OC00LjY3ODY3OSAzLjk0ODYtNC42Nzg2NzkgMy43OTQzNTctNC43MTk4MUMzLjY0MDExNS00Ljc1MDY1OSAzLjU1Nzg1My00Ljc2MDk0MiAzLjQ3NTU5LTQuNzYwOTQyQzMuMjI4ODAzLTQuNzYwOTQyIDMuMDEyODY0LTQuNTk2NDE3IDIuOTcxNzMyLTQuNDAxMDQzQzIuOTQwODg0LTQuMjA1NjcgMy4xMDU0MDktNC4wODIyNzYgMy4zNzI3NjItNC4wODIyNzZDMy40MzQ0NTktNC4wODIyNzYgMy40ODU4NzMtNC4wOTI1NTkgMy41OTg5ODQtNC4xMTMxMjRDMy43MjIzNzgtNC4xNDM5NzMgMy44MjUyMDYtNC4xNTQyNTYgMy45MDc0NjgtNC4xNTQyNTZDNC4wNDExNDUtNC4xNTQyNTYgNC4xMTMxMjQtNC4xMzM2OSA0LjE2NDUzOS00LjA3MTk5M0M0LjU1NTI4NS0zLjY0MDExNSA0LjY5OTI0NS0yLjg1ODYyMiA0LjU2NTU2OC0yLjAxNTQzMUM0LjM5MDc2LS45ODcxNSAzLjgzNTQ4OS0uMzgwNDY0IDMuMDc0NTYxLS4zODA0NjRDMi41NjA0Mi0uMzgwNDY0IDIuMDg3NDExLS42MTY5NjkgMS44MDk3NzUtMS4wMTc5OThMMi42NDI2ODItNi4wMDUxNjJaJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PSc1Ni40MTMyNjcnIHk9JzY1Ljc2NjA0MicgeGxpbms6aHJlZj0nI2cxMi05OCcvPgo8dXNlIHg9JzY4Ljg4NTUzMycgeT0nNjUuNzY2MDQyJyB4bGluazpocmVmPScjZzIyLTYxJy8+Cjx1c2UgeD0nODIuODIyMjE0JyB5PSc2NS43NjYwNDInIHhsaW5rOmhyZWY9JyNnMjItOTEnLz4KPHVzZSB4PSc4Ni42ODU1ODUnIHk9JzY1Ljc2NjA0MicgeGxpbms6aHJlZj0nI2cxLTg4Jy8+Cjx1c2UgeD0nOTYuNzU1Nzg0JyB5PSc2MC43MDMxOTUnIHhsaW5rOmhyZWY9JyNnMTAtODQnLz4KPHVzZSB4PScxMDQuMzAzMjI2JyB5PSc2NS43NjYwNDInIHhsaW5rOmhyZWY9JyNnMS04OCcvPgo8dXNlIHg9JzExNC4zNzM0MjQnIHk9JzY1Ljc2NjA0MicgeGxpbms6aHJlZj0nI2cyMi05MycvPgo8dXNlIHg9JzExOC4yMzY3OTUnIHk9JzYwLjcwMzE5NScgeGxpbms6aHJlZj0nI2czLTAnLz4KPHVzZSB4PScxMjYuMjU2Mzk3JyB5PSc2MC43MDMxOTUnIHhsaW5rOmhyZWY9JyNnMTctNDknLz4KPHVzZSB4PScxMzEuOTE1MjA3JyB5PSc2NS43NjYwNDInIHhsaW5rOmhyZWY9JyNnMS04OCcvPgo8dXNlIHg9JzE0MS45ODU0MDYnIHk9JzYwLjcwMzE5NScgeGxpbms6aHJlZj0nI2cxMC04NCcvPgo8dXNlIHg9JzE0OS41MzI4NDcnIHk9JzY1Ljc2NjA0MicgeGxpbms6aHJlZj0nI2cxLTEyMicvPgo8L2c+Cjwvc3ZnPg==) . The generalized least squares (GLSQ, or
“pre-whitening” solution) is derived by pre-multiplying the
matrix-vector equation by a symmetric matrix
. The generalized least squares (GLSQ, or
“pre-whitening” solution) is derived by pre-multiplying the
matrix-vector equation by a symmetric matrix  such
that
such
that  , where is
the temporal autocorrelation matrix. Then the equation becomes
, where is
the temporal autocorrelation matrix. Then the equation becomes
 , and under
the assumption that
, and under
the assumption that ![E[\epsilon \epsilon^T] = \sigma^2
\mathbf{R}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuMi4xIC0tPgo8c3ZnIHZlcnNpb249JzEuMScgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluaycgd2lkdGg9JzgxLjkzNjE2NnB0JyBoZWlnaHQ9JzE1LjQ4NzkyNXB0JyB2aWV3Qm94PSc1Ni4zOTkzNzIgNTMuNzUyMDE1IDgxLjkzNjE2NiAxNS40ODc5MjUnPgo8ZGVmcz4KPHBhdGggaWQ9J2cxLTgyJyBkPSdNOS45MzUzNDUtLjM0NzM5QzkuNjg1MjI1LS4zNDczOSA5LjUwNDU4Mi0uNDMwNzYzIDkuMzY1NjI2LS42MTE0MDZMNi41NzI2MTMtNC41NzE2NDhDNy4zOTI0NTMtNC44MzU2NjUgNy43Mzk4NDItNS4wMTYzMDcgOC4xMjg5MTktNS4zNjM2OTdDOC41MzE4OTEtNS43Mzg4NzggOC43NTQyMi02LjI5NDcwMSA4Ljc1NDIyLTYuOTIwMDAzQzguNzU0MjItOC41MTc5OTUgNy4zNzg1NTctOS4zOTM0MTcgNC44MzU2NjUtOS4zOTM0MTdILjM2MTI4NVYtOS4wNDYwMjhDMS4zODk1NTktOC45NzY1NSAxLjU4NDA5Ny04Ljc2ODExNiAxLjU4NDA5Ny03Ljc2NzYzNFYtMS42MjU3ODRDMS41ODQwOTctLjYxMTQwNiAxLjQ0NTE0MS0uNDcyNDUgLjM2MTI4NS0uMzQ3MzlWMEg1LjA1Nzk5NFYtLjM0NzM5QzMuOTc0MTM4LS40ODYzNDYgMy44MzUxODItLjYzOTE5NyAzLjgzNTE4Mi0xLjYyNTc4NFYtNC4zNDkzMTlINC4yMTAzNjNMNy4wODY3NSAwSDkuOTM1MzQ1Vi0uMzQ3MzlaTTMuODM1MTgyLTguMzM3MzUzQzMuODM1MTgyLTguNDIwNzI2IDMuODkwNzY1LTguNjI5MTYgMy45MzI0NTEtOC43MTI1MzNDNC4wMTU4MjUtOC44NTE0ODkgNC4yMzgxNTQtOC45MjA5NjcgNC41ODU1NDQtOC45MjA5NjdDNS44NjM5MzgtOC45MjA5NjcgNi4zNzgwNzUtOC4zMjM0NTcgNi4zNzgwNzUtNi44NjQ0MkM2LjM3ODA3NS01Ljk3NTEwMyA2LjE2OTY0MS01LjQzMzE3NSA1LjcyNDk4Mi01LjE0MTM2N0M1LjM2MzY5Ny00LjkwNTE0MiA0Ljg5MTI0Ny00LjgwNzg3MyAzLjgzNTE4Mi00Ljc5Mzk3OFYtOC4zMzczNTNaJy8+CjxwYXRoIGlkPSdnMTItNTAnIGQ9J000Ljg4NDMzNS0xLjQwODc0NUw0Ljc1MDY1OS0xLjQ2MDE1OUM0LjM3MDE5NS0uODc0MDM5IDQuMjM2NTE4LS43ODE0OTQgMy43NzM3OTItLjc4MTQ5NEgxLjMxNjJMMy4wNDM3MTItMi41OTEyNjhDMy45NTg4ODItMy41NDc1NyA0LjM1OTkxMi00LjMyOTA2NCA0LjM1OTkxMi01LjEzMTEyM0M0LjM1OTkxMi02LjE1OTQwNCAzLjUyNzAwNC02Ljk1MTE4IDIuNDU3NTkyLTYuOTUxMThDMS44OTIwMzctNi45NTExOCAxLjM1NzMzMS02LjcyNDk1OSAuOTc2ODY3LTYuMzEzNjQ2Qy42NDc4MTctNS45NjQwMzEgLjQ5MzU3NS01LjYzNDk4MSAuMzE4NzY3LTQuOTA0OTAxTC41MzQ3MDYtNC44NTM0ODdDLjk0NjAxOS01Ljg2MTIwMiAxLjMxNjItNi4xOTAyNTIgMi4wMjU3MTQtNi4xOTAyNTJDMi44ODk0Ny02LjE5MDI1MiAzLjQ3NTU5LTUuNjA0MTMyIDMuNDc1NTktNC43NDAzNzZDMy40NzU1OS0zLjkzODMxNyAzLjAwMjU4MS0yLjk4MjAxNSAyLjEzODgyNS0yLjA2Njg0NUwuMzA4NDg0LS4xMjMzOTRWMEg0LjMxODc4MUw0Ljg4NDMzNS0xLjQwODc0NVonLz4KPHVzZSBpZD0nZzctMTAxJyB4bGluazpocmVmPScjZzMtMTAxJyB0cmFuc2Zvcm09J3NjYWxlKDEuMzUxMzQxKScvPgo8dXNlIGlkPSdnNy0xMTUnIHhsaW5rOmhyZWY9JyNnMy0xMTUnIHRyYW5zZm9ybT0nc2NhbGUoMS4zNTEzNDEpJy8+CjxwYXRoIGlkPSdnMy0xMDEnIGQ9J000LjM1OTkxMi0xLjI4NTM1MUM0LjAzMDg2Mi0uNjM3NTM0IDMuNjA5MjY3LS4zODA0NjQgMi44Njg5MDQtLjM4MDQ2NEMyLjM3NTMyOS0uMzgwNDY0IDEuOTg0NTgzLS41MDM4NTggMS43Mzc3OTUtLjc1MDY0NUMxLjU2Mjk4Ny0uOTM1NzM2IDEuNTIxODU2LTEuMTQxMzkyIDEuNTczMjctMS40NzA0NDJDMS42NzYwOTgtMi4wNzcxMjggMi4wODc0MTEtMi40Njc4NzUgMi42MzI0LTIuNDY3ODc1QzIuNzM1MjI4LTIuNDY3ODc1IDIuODI3NzczLTIuNDU3NTkyIDIuOTMwNjAxLTIuNDM3MDI2QzMuMDUzOTk1LTIuNDA2MTc4IDMuMTc3Mzg5LTIuMzg1NjEyIDMuMjgwMjE3LTIuMzg1NjEyQzMuNTg4NzAxLTIuMzg1NjEyIDMuODM1NDg5LTIuNTI5NTcyIDMuODY2MzM3LTIuNzE0NjYyQzMuODk3MTg1LTIuODc5MTg3IDMuNzg0MDc1LTIuOTYxNDUgMy41NDc1Ny0yLjk2MTQ1QzMuNDY1MzA3LTIuOTYxNDUgMy4zODMwNDUtMi45NjE0NSAzLjE5Nzk1NC0yLjk0MDg4NEMyLjg0ODMzOS0yLjkxMDAzNiAyLjc2NjA3Ni0yLjg5OTc1MyAyLjY3MzUzMS0yLjg5OTc1M0MyLjE0OTEwOC0yLjg5OTc1MyAxLjg3MTQ3Mi0zLjI1OTY1MSAxLjk2NDAxNy0zLjgxNDkyM0MyLjA2Njg0NS00LjQyMTYwOSAyLjU4MDk4Ni00LjkxNTE4NCAzLjExNTY5Mi00LjkxNTE4NEMzLjQ4NTg3My00LjkxNTE4NCAzLjY5MTUyOS00Ljc1MDY1OSAzLjc1MzIyNi00LjQyMTYwOUMzLjc3Mzc5Mi00LjI2NzM2NyAzLjc5NDM1Ny00LjE4NTEwNCAzLjgwNDY0LTQuMTY0NTM5QzMuODc2NjItMy45MzgzMTcgNC4wMzA4NjItMy44MTQ5MjMgNC4yMzY1MTgtMy44MTQ5MjNDNC41MDM4NzEtMy44MTQ5MjMgNC43NzEyMjQtNC4wNDExNDUgNC44MTIzNTYtNC4zMjkwNjRDNC45MDQ5MDEtNC44NzQwNTMgNC4yNzc2NDktNS4yNzUwODIgMy4zMjEzNDgtNS4yNzUwODJDMi42NzM1MzEtNS4yNzUwODIgMi4xNjk2NzMtNS4xMzExMjMgMS43MTcyMjktNC44MTIzNTZDMS4yOTU2MzQtNC41MjQ0MzcgMS4wNjk0MTItNC4yMDU2NyAxLjAwNzcxNS0zLjgyNTIwNkMuOTU2MzAxLTMuNDg1ODczIDEuMDU5MTMtMy4xNzczODkgMS4yNzUwNjktMi45ODIwMTVDMS40MDg3NDUtMi44ODk0NyAxLjQ5MTAwOC0yLjgzODA1NiAxLjc4OTIwOS0yLjY4MzgxNEMxLjM0NzA0OC0yLjUzOTg1NCAxLjEzMTEwOS0yLjQyNjc0MyAuOTE1MTctMi4yMjEwODdDLjY4ODk0OC0yLjAwNTE0OCAuNTAzODU4LTEuNjg2MzgxIC40NjI3MjctMS4zODgxOEMuMzA4NDg0LS41MDM4NTggMS4xMTA1NDQgLjEzMzY3NyAyLjM4NTYxMiAuMTMzNjc3QzMuNTI3MDA0IC4xMzM2NzcgNC4yMzY1MTgtLjI4NzkxOSA0LjU4NjEzNC0xLjE5MjgwNkw0LjM1OTkxMi0xLjI4NTM1MVonLz4KPHBhdGggaWQ9J2czLTExNScgZD0nTTYuNzU1ODA3LTQuMjQ2ODAxTDYuOTEwMDQ5LTUuMTQxNDA2SDQuNTc1ODUxQzMuNzYzNTA5LTUuMTQxNDA2IDMuMTg3NjcxLTUuMDQ4ODYgMi42ODM4MTQtNC44NDMyMDRDMS42MDQxMTktNC4zOTA3NiAuOTA0ODg3LTMuNTg4NzAxIC43NTA2NDUtMi42MzI0Qy42Mzc1MzQtMS45NjQwMTcgLjc4MTQ5NC0xLjI4NTM1MSAxLjE2MTk1OC0uNzUwNjQ1QzEuNTkzODM2LS4xMzM2NzcgMi4xMzg4MjUgLjEzMzY3NyAyLjk1MTE2NyAuMTMzNjc3QzMuNjUwMzk4IC4xMzM2NzcgNC4yNzc2NDktLjA4MjI2MiA0LjgyMjYzOC0uNTAzODU4QzUuMzU3MzQ1LS45MjU0NTMgNS43Mzc4MDktMS41MTE1NzMgNS44MzAzNTQtMi4wNjY4NDVDNS45NTM3NDgtMi44NDgzMzkgNS40OTEwMjEtMy42MTk1NSA0LjUwMzg3MS00LjI0NjgwMUg2Ljc1NTgwN1pNNC4wMjA1NzktNC4yNDY4MDFDNC43NTA2NTktMy4zMzE2MzEgNC44ODQzMzUtMi45NDA4ODQgNC43NDAzNzYtMi4wOTc2OTNDNC41NjU1NjgtMS4wMjgyODEgMy45MjgwMzQtLjMwODQ4NCAzLjE2NzEwNi0uMzA4NDg0QzIuMjIxMDg3LS4zMDg0ODQgMS42MTQ0MDEtMS4zNDcwNDggMS44MjAwNTgtMi42MTE4MzRDMS45ODQ1ODMtMy41OTg5ODQgMi43MzUyMjgtNC4yNDY4MDEgMy43MDE4MTItNC4yNDY4MDFINC4wMjA1NzlaJy8+CjxwYXRoIGlkPSdnMTMtNjEnIGQ9J003LjA2NDI5MS0zLjM2MjQ3OUM3LjIxODUzMy0zLjM2MjQ3OSA3LjQxMzkwNy0zLjM2MjQ3OSA3LjQxMzkwNy0zLjU2ODEzNVM3LjIxODUzMy0zLjc3Mzc5MiA3LjA3NDU3NC0zLjc3Mzc5MkguOTE1MTdDLjc3MTIxMS0zLjc3Mzc5MiAuNTc1ODM3LTMuNzczNzkyIC41NzU4MzctMy41NjgxMzVTLjc3MTIxMS0zLjM2MjQ3OSAuOTI1NDUzLTMuMzYyNDc5SDcuMDY0MjkxWk03LjA3NDU3NC0xLjM2NzYxNEM3LjIxODUzMy0xLjM2NzYxNCA3LjQxMzkwNy0xLjM2NzYxNCA3LjQxMzkwNy0xLjU3MzI3UzcuMjE4NTMzLTEuNzc4OTI2IDcuMDY0MjkxLTEuNzc4OTI2SC45MjU0NTNDLjc3MTIxMS0xLjc3ODkyNiAuNTc1ODM3LTEuNzc4OTI2IC41NzU4MzctMS41NzMyN1MuNzcxMjExLTEuMzY3NjE0IC45MTUxNy0xLjM2NzYxNEg3LjA3NDU3NFonLz4KPHBhdGggaWQ9J2cxMy05MScgZD0nTTIuNjIyMTE3IDIuNTcwNzAzVjIuMTU5MzlIMS42MjQ2ODRWLTcuMzAwNzk2SDIuNjIyMTE3Vi03LjcxMjEwOEgxLjIxMzM3MlYyLjU3MDcwM0gyLjYyMjExN1onLz4KPHBhdGggaWQ9J2cxMy05MycgZD0nTTEuNjM0OTY3LTcuNzEyMTA4SC4yMjYyMjJWLTcuMzAwNzk2SDEuMjIzNjU1VjIuMTU5MzlILjIyNjIyMlYyLjU3MDcwM0gxLjYzNDk2N1YtNy43MTIxMDhaJy8+Cjx1c2UgaWQ9J2cxNy02MScgeGxpbms6aHJlZj0nI2cxMy02MScgdHJhbnNmb3JtPSdzY2FsZSgxLjM1MTM0MSknLz4KPHVzZSBpZD0nZzE3LTkxJyB4bGluazpocmVmPScjZzEzLTkxJyB0cmFuc2Zvcm09J3NjYWxlKDEuMzUxMzQxKScvPgo8dXNlIGlkPSdnMTctOTMnIHhsaW5rOmhyZWY9JyNnMTMtOTMnIHRyYW5zZm9ybT0nc2NhbGUoMS4zNTEzNDEpJy8+Cjx1c2UgaWQ9J2c5LTY5JyB4bGluazpocmVmPScjZzUtNjknIHRyYW5zZm9ybT0nc2NhbGUoMS4zNTEzNDEpJy8+CjxwYXRoIGlkPSdnNS02OScgZD0nTTYuNTE5MzAyLTYuNzE0Njc2SDEuNDA4NzQ1Vi02LjU1MDE1MUMyLjA0NjI3OS02LjQ4ODQ1NCAyLjIwMDUyMi02LjQwNjE5MSAyLjIwMDUyMi02LjEyODU1NUMyLjIwMDUyMi02LjAxNTQ0NSAyLjEzODgyNS01LjY1NTU0NiAyLjA4NzQxMS01LjQ3MDQ1NkwuODIyNjI1LS45MjU0NTNDLjY0NzgxNy0uMzM5MzMzIC41NjU1NTUtLjI2NzM1My0uMDEwMjgzLS4xNjQ1MjVWMEg1LjIwMzEwMkw1Ljg0MDYzNy0xLjY2NTgxNUw1LjY3NjExMi0xLjc0ODA3OEM1LjE5MjgyLTEuMDg5OTc4IDQuOTI1NDY3LS44MjI2MjUgNC40ODMzMDYtLjYxNjk2OUM0LjEwMjg0Mi0uNDQyMTYxIDMuNDAzNjExLS4zMzkzMzMgMi42MzI0LS4zMzkzMzNDMi4wNTY1NjItLjMzOTMzMyAxLjgwOTc3NS0uNDQyMTYxIDEuODA5Nzc1LS42ODg5NDhDMS44MDk3NzUtLjgwMjA1OSAxLjkyMjg4Ni0xLjI4NTM1MSAyLjE3OTk1Ni0yLjE5MDIzOUMyLjMxMzYzMy0yLjY0MjY4MiAyLjQwNjE3OC0yLjk4MjAxNSAyLjUwOTAwNi0zLjM3Mjc2MkMyLjg2ODkwNC0zLjM1MjE5NiAzLjE4NzY3MS0zLjM0MTkxNCAzLjMxMTA2NS0zLjM0MTkxNEMzLjcxMjA5NS0zLjM1MjE5NiA0LjAwMDAxNC0zLjI5MDUgNC4xMTMxMjQtMy4xODc2NzFDNC4xNjQ1MzktMy4xMzYyNTcgNC4xODUxMDQtMy4wNDM3MTIgNC4xODUxMDQtMi44Njg5MDRTNC4xNjQ1MzktMi41NjA0MiA0LjExMzEyNC0yLjMzNDE5OEw0LjMxODc4MS0yLjI4Mjc4NEw1LjAxODAxMi00LjY2ODM5Nkw0LjgzMjkyMS00LjcwOTUyOEM0LjQ0MjE3NC0zLjgzNTQ4OSA0LjM0OTYyOS0zLjc3Mzc5MiAzLjQxMzg5My0zLjczMjY2QzMuMjkwNS0zLjczMjY2IDIuOTYxNDUtMy43MjIzNzggMi42MDE1NTEtMy43MTIwOTVMMy4yODAyMTctNi4xMDc5OUMzLjM0MTkxNC02LjMzNDIxMiAzLjQ1NTAyNS02LjM3NTM0MyA0LjAzMDg2Mi02LjM3NTM0M0M1LjY0NTI2My02LjM3NTM0MyA2LjAwNTE2Mi02LjI0MTY2NiA2LjAwNTE2Mi01LjYyNDY5OEM2LjAwNTE2Mi01LjQ5MTAyMSA1Ljk5NDg3OS01LjMzNjc3OSA1Ljk4NDU5Ni01LjE2MTk3MUw2LjIwMDUzNS01LjE0MTQwNkw2LjUxOTMwMi02LjcxNDY3NlonLz4KPHBhdGggaWQ9J2c1LTg0JyBkPSdNNi41MDkwMi02LjcxNDY3NkgxLjAzODU2NEwuNjA2Njg2LTUuMTMxMTIzTC43OTE3NzYtNS4wODk5OTJDMS4zMzY3NjUtNi4yMDA1MzUgMS42NjU4MTUtNi4zNzUzNDMgMy4yMzkwODYtNi4zNTQ3NzdMMS43NTgzNjEtLjkyNTQ1M0MxLjU5MzgzNi0uMzgwNDY0IDEuMzQ3MDQ4LS4yMTU5MzkgLjY2ODM4My0uMTY0NTI1VjBIMy42NTAzOThWLS4xNjQ1MjVDMy40NzU1OS0uMTc0ODA4IDMuMzIxMzQ4LS4xOTUzNzMgMy4yNTk2NTEtLjE5NTM3M0MyLjg0ODMzOS0uMjI2MjIyIDIuNzI0OTQ1LS4zMTg3NjcgMi43MjQ5NDUtLjYyNzI1MUMyLjcyNDk0NS0uNzYwOTI4IDIuNzU1NzkzLS44ODQzMjIgMi44NDgzMzktMS4yMzM5MzdMNC4yNzc2NDktNi4zNTQ3NzdINC44NDMyMDRDNS41ODM1NjYtNi4zNTQ3NzcgNS45MTI2MTYtNi4wOTc3MDcgNS45MTI2MTYtNS41MjE4N0M1LjkxMjYxNi01LjM4ODE5MyA1LjkwMjMzNC01LjIzMzk1MSA1Ljg4MTc2OC01LjA1OTE0M0w2LjA1NjU3Ni01LjAzODU3N0w2LjUwOTAyLTYuNzE0Njc2WicvPgo8L2RlZnM+CjxnIGlkPSdwYWdlMSc+Cjx1c2UgeD0nNTYuNDEzMjY3JyB5PSc2NS43NjYwNDInIHhsaW5rOmhyZWY9JyNnOS02OScvPgo8dXNlIHg9JzY1Ljk1MzQ1MicgeT0nNjUuNzY2MDQyJyB4bGluazpocmVmPScjZzE3LTkxJy8+Cjx1c2UgeD0nNjkuODE2ODIzJyB5PSc2NS43NjYwNDInIHhsaW5rOmhyZWY9JyNnNy0xMDEnLz4KPHVzZSB4PSc3Ny4wOTczMTgnIHk9JzY1Ljc2NjA0MicgeGxpbms6aHJlZj0nI2c3LTEwMScvPgo8dXNlIHg9Jzg0LjM3NzgxMicgeT0nNjAuNzAzMTk1JyB4bGluazpocmVmPScjZzUtODQnLz4KPHVzZSB4PSc5MS45MjUyNTQnIHk9JzY1Ljc2NjA0MicgeGxpbms6aHJlZj0nI2cxNy05MycvPgo8dXNlIHg9Jzk4Ljg4ODA4NycgeT0nNjUuNzY2MDQyJyB4bGluazpocmVmPScjZzE3LTYxJy8+Cjx1c2UgeD0nMTEyLjgyNDc2NycgeT0nNjUuNzY2MDQyJyB4bGluazpocmVmPScjZzctMTE1Jy8+Cjx1c2UgeD0nMTIyLjc0MTM3NCcgeT0nNjAuNzAzMTk1JyB4bGluazpocmVmPScjZzEyLTUwJy8+Cjx1c2UgeD0nMTI4LjQwMDE5MicgeT0nNjUuNzY2MDQyJyB4bGluazpocmVmPScjZzEtODInLz4KPC9nPgo8L3N2Zz4=) ,
, ![E[\mathbf{W}\epsilon \epsilon^T\mathbf{W}] =
\sigma^2\mathbf{I}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuMi4xIC0tPgo8c3ZnIHZlcnNpb249JzEuMScgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluaycgd2lkdGg9JzEwNS4wMzc1OHB0JyBoZWlnaHQ9JzE1LjQ4NzkyNXB0JyB2aWV3Qm94PSc1Ni4zOTkzNzIgNTMuNzUyMDE1IDEwNS4wMzc1OCAxNS40ODc5MjUnPgo8ZGVmcz4KPHBhdGggaWQ9J2cxMi01MCcgZD0nTTQuODg0MzM1LTEuNDA4NzQ1TDQuNzUwNjU5LTEuNDYwMTU5QzQuMzcwMTk1LS44NzQwMzkgNC4yMzY1MTgtLjc4MTQ5NCAzLjc3Mzc5Mi0uNzgxNDk0SDEuMzE2MkwzLjA0MzcxMi0yLjU5MTI2OEMzLjk1ODg4Mi0zLjU0NzU3IDQuMzU5OTEyLTQuMzI5MDY0IDQuMzU5OTEyLTUuMTMxMTIzQzQuMzU5OTEyLTYuMTU5NDA0IDMuNTI3MDA0LTYuOTUxMTggMi40NTc1OTItNi45NTExOEMxLjg5MjAzNy02Ljk1MTE4IDEuMzU3MzMxLTYuNzI0OTU5IC45NzY4NjctNi4zMTM2NDZDLjY0NzgxNy01Ljk2NDAzMSAuNDkzNTc1LTUuNjM0OTgxIC4zMTg3NjctNC45MDQ5MDFMLjUzNDcwNi00Ljg1MzQ4N0MuOTQ2MDE5LTUuODYxMjAyIDEuMzE2Mi02LjE5MDI1MiAyLjAyNTcxNC02LjE5MDI1MkMyLjg4OTQ3LTYuMTkwMjUyIDMuNDc1NTktNS42MDQxMzIgMy40NzU1OS00Ljc0MDM3NkMzLjQ3NTU5LTMuOTM4MzE3IDMuMDAyNTgxLTIuOTgyMDE1IDIuMTM4ODI1LTIuMDY2ODQ1TC4zMDg0ODQtLjEyMzM5NFYwSDQuMzE4NzgxTDQuODg0MzM1LTEuNDA4NzQ1WicvPgo8dXNlIGlkPSdnNy0xMDEnIHhsaW5rOmhyZWY9JyNnMy0xMDEnIHRyYW5zZm9ybT0nc2NhbGUoMS4zNTEzNDEpJy8+Cjx1c2UgaWQ9J2c3LTExNScgeGxpbms6aHJlZj0nI2czLTExNScgdHJhbnNmb3JtPSdzY2FsZSgxLjM1MTM0MSknLz4KPHBhdGggaWQ9J2czLTEwMScgZD0nTTQuMzU5OTEyLTEuMjg1MzUxQzQuMDMwODYyLS42Mzc1MzQgMy42MDkyNjctLjM4MDQ2NCAyLjg2ODkwNC0uMzgwNDY0QzIuMzc1MzI5LS4zODA0NjQgMS45ODQ1ODMtLjUwMzg1OCAxLjczNzc5NS0uNzUwNjQ1QzEuNTYyOTg3LS45MzU3MzYgMS41MjE4NTYtMS4xNDEzOTIgMS41NzMyNy0xLjQ3MDQ0MkMxLjY3NjA5OC0yLjA3NzEyOCAyLjA4NzQxMS0yLjQ2Nzg3NSAyLjYzMjQtMi40Njc4NzVDMi43MzUyMjgtMi40Njc4NzUgMi44Mjc3NzMtMi40NTc1OTIgMi45MzA2MDEtMi40MzcwMjZDMy4wNTM5OTUtMi40MDYxNzggMy4xNzczODktMi4zODU2MTIgMy4yODAyMTctMi4zODU2MTJDMy41ODg3MDEtMi4zODU2MTIgMy44MzU0ODktMi41Mjk1NzIgMy44NjYzMzctMi43MTQ2NjJDMy44OTcxODUtMi44NzkxODcgMy43ODQwNzUtMi45NjE0NSAzLjU0NzU3LTIuOTYxNDVDMy40NjUzMDctMi45NjE0NSAzLjM4MzA0NS0yLjk2MTQ1IDMuMTk3OTU0LTIuOTQwODg0QzIuODQ4MzM5LTIuOTEwMDM2IDIuNzY2MDc2LTIuODk5NzUzIDIuNjczNTMxLTIuODk5NzUzQzIuMTQ5MTA4LTIuODk5NzUzIDEuODcxNDcyLTMuMjU5NjUxIDEuOTY0MDE3LTMuODE0OTIzQzIuMDY2ODQ1LTQuNDIxNjA5IDIuNTgwOTg2LTQuOTE1MTg0IDMuMTE1NjkyLTQuOTE1MTg0QzMuNDg1ODczLTQuOTE1MTg0IDMuNjkxNTI5LTQuNzUwNjU5IDMuNzUzMjI2LTQuNDIxNjA5QzMuNzczNzkyLTQuMjY3MzY3IDMuNzk0MzU3LTQuMTg1MTA0IDMuODA0NjQtNC4xNjQ1MzlDMy44NzY2Mi0zLjkzODMxNyA0LjAzMDg2Mi0zLjgxNDkyMyA0LjIzNjUxOC0zLjgxNDkyM0M0LjUwMzg3MS0zLjgxNDkyMyA0Ljc3MTIyNC00LjA0MTE0NSA0LjgxMjM1Ni00LjMyOTA2NEM0LjkwNDkwMS00Ljg3NDA1MyA0LjI3NzY0OS01LjI3NTA4MiAzLjMyMTM0OC01LjI3NTA4MkMyLjY3MzUzMS01LjI3NTA4MiAyLjE2OTY3My01LjEzMTEyMyAxLjcxNzIyOS00LjgxMjM1NkMxLjI5NTYzNC00LjUyNDQzNyAxLjA2OTQxMi00LjIwNTY3IDEuMDA3NzE1LTMuODI1MjA2Qy45NTYzMDEtMy40ODU4NzMgMS4wNTkxMy0zLjE3NzM4OSAxLjI3NTA2OS0yLjk4MjAxNUMxLjQwODc0NS0yLjg4OTQ3IDEuNDkxMDA4LTIuODM4MDU2IDEuNzg5MjA5LTIuNjgzODE0QzEuMzQ3MDQ4LTIuNTM5ODU0IDEuMTMxMTA5LTIuNDI2NzQzIC45MTUxNy0yLjIyMTA4N0MuNjg4OTQ4LTIuMDA1MTQ4IC41MDM4NTgtMS42ODYzODEgLjQ2MjcyNy0xLjM4ODE4Qy4zMDg0ODQtLjUwMzg1OCAxLjExMDU0NCAuMTMzNjc3IDIuMzg1NjEyIC4xMzM2NzdDMy41MjcwMDQgLjEzMzY3NyA0LjIzNjUxOC0uMjg3OTE5IDQuNTg2MTM0LTEuMTkyODA2TDQuMzU5OTEyLTEuMjg1MzUxWicvPgo8cGF0aCBpZD0nZzMtMTE1JyBkPSdNNi43NTU4MDctNC4yNDY4MDFMNi45MTAwNDktNS4xNDE0MDZINC41NzU4NTFDMy43NjM1MDktNS4xNDE0MDYgMy4xODc2NzEtNS4wNDg4NiAyLjY4MzgxNC00Ljg0MzIwNEMxLjYwNDExOS00LjM5MDc2IC45MDQ4ODctMy41ODg3MDEgLjc1MDY0NS0yLjYzMjRDLjYzNzUzNC0xLjk2NDAxNyAuNzgxNDk0LTEuMjg1MzUxIDEuMTYxOTU4LS43NTA2NDVDMS41OTM4MzYtLjEzMzY3NyAyLjEzODgyNSAuMTMzNjc3IDIuOTUxMTY3IC4xMzM2NzdDMy42NTAzOTggLjEzMzY3NyA0LjI3NzY0OS0uMDgyMjYyIDQuODIyNjM4LS41MDM4NThDNS4zNTczNDUtLjkyNTQ1MyA1LjczNzgwOS0xLjUxMTU3MyA1LjgzMDM1NC0yLjA2Njg0NUM1Ljk1Mzc0OC0yLjg0ODMzOSA1LjQ5MTAyMS0zLjYxOTU1IDQuNTAzODcxLTQuMjQ2ODAxSDYuNzU1ODA3Wk00LjAyMDU3OS00LjI0NjgwMUM0Ljc1MDY1OS0zLjMzMTYzMSA0Ljg4NDMzNS0yLjk0MDg4NCA0Ljc0MDM3Ni0yLjA5NzY5M0M0LjU2NTU2OC0xLjAyODI4MSAzLjkyODAzNC0uMzA4NDg0IDMuMTY3MTA2LS4zMDg0ODRDMi4yMjEwODctLjMwODQ4NCAxLjYxNDQwMS0xLjM0NzA0OCAxLjgyMDA1OC0yLjYxMTgzNEMxLjk4NDU4My0zLjU5ODk4NCAyLjczNTIyOC00LjI0NjgwMSAzLjcwMTgxMi00LjI0NjgwMUg0LjAyMDU3OVonLz4KPHBhdGggaWQ9J2cxLTczJyBkPSdNMS41NzAyMDEtMS4zMzM5NzZDMS41NzAyMDEtLjYzOTE5NyAxLjMyMDA4MS0uNDQ0NjU5IC4yNzc5MTItLjM0NzM5VjBINS4xNDEzNjdWLS4zNDczOUM0LjA4NTMwMy0uNDE2ODY4IDMuODIxMjg3LS42MTE0MDYgMy44MjEyODctMS4zMzM5NzZWLTguMDU5NDQxQzMuODIxMjg3LTguNzgyMDExIDQuMTEzMDk0LTkuMDA0MzQxIDUuMTQxMzY3LTkuMDQ2MDI4Vi05LjM5MzQxN0guMjc3OTEyVi05LjA0NjAyOEMxLjI3ODM5NC04Ljk3NjU1IDEuNTcwMjAxLTguNzY4MTE2IDEuNTcwMjAxLTguMDU5NDQxVi0xLjMzMzk3NlonLz4KPHBhdGggaWQ9J2cxLTg3JyBkPSdNMTMuNjMxNTcyLTkuMzkzNDE3SDExLjEwMjU3NVYtOS4wNDYwMjhDMTEuODUyOTM2LTkuMDA0MzQxIDEyLjA2MTM3LTguODY1Mzg1IDEyLjA2MTM3LTguNDM0NjIyQzEyLjA2MTM3LTguMjUzOTc5IDEyLjAzMzU3OS04LjA0NTU0NSAxMS45NjQxMDEtNy44NTEwMDdMMTAuNDA3Nzk1LTMuMDg0ODJMOC45MDcwNzItNy43NTM3MzhDOC43NjgxMTYtOC4xOTgzOTcgOC43MTI1MzMtOC40MDY4MzEgOC43MTI1MzMtOC41MzE4OTFDOC43MTI1MzMtOC44NjUzODUgOC45MjA5NjctOC45OTA0NDUgOS41MzIzNzMtOS4wMzIxMzJDOS41NjAxNjQtOS4wMzIxMzIgOS42Mjk2NDItOS4wMzIxMzIgOS43MTMwMTYtOS4wNDYwMjhWLTkuMzkzNDE3SDUuMzc3NTkyVi05LjA0NjAyOEM1Ljk0NzMxMi05LjAxODIzNiA2LjIyNTIyMy04Ljg5MzE3NiA2LjM3ODA3NS04LjU1OTY4Mkw2Ljg2NDQyLTcuMjI1NzA2TDUuMjI0NzQxLTIuOTQ1ODY1TDMuNTU3MjctOC4wMDM4NTlDMy40ODc3OTMtOC4yMjYxODggMy40NjAwMDEtOC4zMzczNTMgMy40NjAwMDEtOC40NjI0MTNDMy40NjAwMDEtOC44NjUzODUgMy42MjY3NDgtOC45OTA0NDUgNC4zNDkzMTktOS4wNDYwMjhWLTkuMzkzNDE3SC4yNjQwMTZWLTkuMDQ2MDI4Qy44NDc2MzEtOC45NjI2NTQgLjk4NjU4Ny04LjgzNzU5NCAxLjIyMjgxMi04LjE1NjcxTDQuMTY4Njc2IC4yMDg0MzRINC41NTc3NTNMNy4xNDIzMzItNi40MTk3NjJMOS41MTg0NzggLjIwODQzNEg5Ljg5MzY1OEwxMi42NzI3NzYtOC4xNTY3MUMxMi44NTM0MTktOC43MTI1MzMgMTMuMTczMDE3LTkuMDA0MzQxIDEzLjYzMTU3Mi05LjA0NjAyOFYtOS4zOTM0MTdaJy8+CjxwYXRoIGlkPSdnMTMtNjEnIGQ9J003LjA2NDI5MS0zLjM2MjQ3OUM3LjIxODUzMy0zLjM2MjQ3OSA3LjQxMzkwNy0zLjM2MjQ3OSA3LjQxMzkwNy0zLjU2ODEzNVM3LjIxODUzMy0zLjc3Mzc5MiA3LjA3NDU3NC0zLjc3Mzc5MkguOTE1MTdDLjc3MTIxMS0zLjc3Mzc5MiAuNTc1ODM3LTMuNzczNzkyIC41NzU4MzctMy41NjgxMzVTLjc3MTIxMS0zLjM2MjQ3OSAuOTI1NDUzLTMuMzYyNDc5SDcuMDY0MjkxWk03LjA3NDU3NC0xLjM2NzYxNEM3LjIxODUzMy0xLjM2NzYxNCA3LjQxMzkwNy0xLjM2NzYxNCA3LjQxMzkwNy0xLjU3MzI3UzcuMjE4NTMzLTEuNzc4OTI2IDcuMDY0MjkxLTEuNzc4OTI2SC45MjU0NTNDLjc3MTIxMS0xLjc3ODkyNiAuNTc1ODM3LTEuNzc4OTI2IC41NzU4MzctMS41NzMyN1MuNzcxMjExLTEuMzY3NjE0IC45MTUxNy0xLjM2NzYxNEg3LjA3NDU3NFonLz4KPHBhdGggaWQ9J2cxMy05MScgZD0nTTIuNjIyMTE3IDIuNTcwNzAzVjIuMTU5MzlIMS42MjQ2ODRWLTcuMzAwNzk2SDIuNjIyMTE3Vi03LjcxMjEwOEgxLjIxMzM3MlYyLjU3MDcwM0gyLjYyMjExN1onLz4KPHBhdGggaWQ9J2cxMy05MycgZD0nTTEuNjM0OTY3LTcuNzEyMTA4SC4yMjYyMjJWLTcuMzAwNzk2SDEuMjIzNjU1VjIuMTU5MzlILjIyNjIyMlYyLjU3MDcwM0gxLjYzNDk2N1YtNy43MTIxMDhaJy8+Cjx1c2UgaWQ9J2cxNy02MScgeGxpbms6aHJlZj0nI2cxMy02MScgdHJhbnNmb3JtPSdzY2FsZSgxLjM1MTM0MSknLz4KPHVzZSBpZD0nZzE3LTkxJyB4bGluazpocmVmPScjZzEzLTkxJyB0cmFuc2Zvcm09J3NjYWxlKDEuMzUxMzQxKScvPgo8dXNlIGlkPSdnMTctOTMnIHhsaW5rOmhyZWY9JyNnMTMtOTMnIHRyYW5zZm9ybT0nc2NhbGUoMS4zNTEzNDEpJy8+Cjx1c2UgaWQ9J2c5LTY5JyB4bGluazpocmVmPScjZzUtNjknIHRyYW5zZm9ybT0nc2NhbGUoMS4zNTEzNDEpJy8+CjxwYXRoIGlkPSdnNS02OScgZD0nTTYuNTE5MzAyLTYuNzE0Njc2SDEuNDA4NzQ1Vi02LjU1MDE1MUMyLjA0NjI3OS02LjQ4ODQ1NCAyLjIwMDUyMi02LjQwNjE5MSAyLjIwMDUyMi02LjEyODU1NUMyLjIwMDUyMi02LjAxNTQ0NSAyLjEzODgyNS01LjY1NTU0NiAyLjA4NzQxMS01LjQ3MDQ1NkwuODIyNjI1LS45MjU0NTNDLjY0NzgxNy0uMzM5MzMzIC41NjU1NTUtLjI2NzM1My0uMDEwMjgzLS4xNjQ1MjVWMEg1LjIwMzEwMkw1Ljg0MDYzNy0xLjY2NTgxNUw1LjY3NjExMi0xLjc0ODA3OEM1LjE5MjgyLTEuMDg5OTc4IDQuOTI1NDY3LS44MjI2MjUgNC40ODMzMDYtLjYxNjk2OUM0LjEwMjg0Mi0uNDQyMTYxIDMuNDAzNjExLS4zMzkzMzMgMi42MzI0LS4zMzkzMzNDMi4wNTY1NjItLjMzOTMzMyAxLjgwOTc3NS0uNDQyMTYxIDEuODA5Nzc1LS42ODg5NDhDMS44MDk3NzUtLjgwMjA1OSAxLjkyMjg4Ni0xLjI4NTM1MSAyLjE3OTk1Ni0yLjE5MDIzOUMyLjMxMzYzMy0yLjY0MjY4MiAyLjQwNjE3OC0yLjk4MjAxNSAyLjUwOTAwNi0zLjM3Mjc2MkMyLjg2ODkwNC0zLjM1MjE5NiAzLjE4NzY3MS0zLjM0MTkxNCAzLjMxMTA2NS0zLjM0MTkxNEMzLjcxMjA5NS0zLjM1MjE5NiA0LjAwMDAxNC0zLjI5MDUgNC4xMTMxMjQtMy4xODc2NzFDNC4xNjQ1MzktMy4xMzYyNTcgNC4xODUxMDQtMy4wNDM3MTIgNC4xODUxMDQtMi44Njg5MDRTNC4xNjQ1MzktMi41NjA0MiA0LjExMzEyNC0yLjMzNDE5OEw0LjMxODc4MS0yLjI4Mjc4NEw1LjAxODAxMi00LjY2ODM5Nkw0LjgzMjkyMS00LjcwOTUyOEM0LjQ0MjE3NC0zLjgzNTQ4OSA0LjM0OTYyOS0zLjc3Mzc5MiAzLjQxMzg5My0zLjczMjY2QzMuMjkwNS0zLjczMjY2IDIuOTYxNDUtMy43MjIzNzggMi42MDE1NTEtMy43MTIwOTVMMy4yODAyMTctNi4xMDc5OUMzLjM0MTkxNC02LjMzNDIxMiAzLjQ1NTAyNS02LjM3NTM0MyA0LjAzMDg2Mi02LjM3NTM0M0M1LjY0NTI2My02LjM3NTM0MyA2LjAwNTE2Mi02LjI0MTY2NiA2LjAwNTE2Mi01LjYyNDY5OEM2LjAwNTE2Mi01LjQ5MTAyMSA1Ljk5NDg3OS01LjMzNjc3OSA1Ljk4NDU5Ni01LjE2MTk3MUw2LjIwMDUzNS01LjE0MTQwNkw2LjUxOTMwMi02LjcxNDY3NlonLz4KPHBhdGggaWQ9J2c1LTg0JyBkPSdNNi41MDkwMi02LjcxNDY3NkgxLjAzODU2NEwuNjA2Njg2LTUuMTMxMTIzTC43OTE3NzYtNS4wODk5OTJDMS4zMzY3NjUtNi4yMDA1MzUgMS42NjU4MTUtNi4zNzUzNDMgMy4yMzkwODYtNi4zNTQ3NzdMMS43NTgzNjEtLjkyNTQ1M0MxLjU5MzgzNi0uMzgwNDY0IDEuMzQ3MDQ4LS4yMTU5MzkgLjY2ODM4My0uMTY0NTI1VjBIMy42NTAzOThWLS4xNjQ1MjVDMy40NzU1OS0uMTc0ODA4IDMuMzIxMzQ4LS4xOTUzNzMgMy4yNTk2NTEtLjE5NTM3M0MyLjg0ODMzOS0uMjI2MjIyIDIuNzI0OTQ1LS4zMTg3NjcgMi43MjQ5NDUtLjYyNzI1MUMyLjcyNDk0NS0uNzYwOTI4IDIuNzU1NzkzLS44ODQzMjIgMi44NDgzMzktMS4yMzM5MzdMNC4yNzc2NDktNi4zNTQ3NzdINC44NDMyMDRDNS41ODM1NjYtNi4zNTQ3NzcgNS45MTI2MTYtNi4wOTc3MDcgNS45MTI2MTYtNS41MjE4N0M1LjkxMjYxNi01LjM4ODE5MyA1LjkwMjMzNC01LjIzMzk1MSA1Ljg4MTc2OC01LjA1OTE0M0w2LjA1NjU3Ni01LjAzODU3N0w2LjUwOTAyLTYuNzE0Njc2WicvPgo8L2RlZnM+CjxnIGlkPSdwYWdlMSc+Cjx1c2UgeD0nNTYuNDEzMjY3JyB5PSc2NS43NjYwNDInIHhsaW5rOmhyZWY9JyNnOS02OScvPgo8dXNlIHg9JzY1Ljk1MzQ1MicgeT0nNjUuNzY2MDQyJyB4bGluazpocmVmPScjZzE3LTkxJy8+Cjx1c2UgeD0nNjkuODE2ODIzJyB5PSc2NS43NjYwNDInIHhsaW5rOmhyZWY9JyNnMS04NycvPgo8dXNlIHg9JzgzLjc2NDUxOScgeT0nNjUuNzY2MDQyJyB4bGluazpocmVmPScjZzctMTAxJy8+Cjx1c2UgeD0nOTEuMDQ1MDE0JyB5PSc2NS43NjYwNDInIHhsaW5rOmhyZWY9JyNnNy0xMDEnLz4KPHVzZSB4PSc5OC4zMjU1MDgnIHk9JzYwLjcwMzE5NScgeGxpbms6aHJlZj0nI2c1LTg0Jy8+Cjx1c2UgeD0nMTA1Ljg3Mjk1JyB5PSc2NS43NjYwNDInIHhsaW5rOmhyZWY9JyNnMS04NycvPgo8dXNlIHg9JzExOS44MjA2NDYnIHk9JzY1Ljc2NjA0MicgeGxpbms6aHJlZj0nI2cxNy05MycvPgo8dXNlIHg9JzEyNi43ODM0NzknIHk9JzY1Ljc2NjA0MicgeGxpbms6aHJlZj0nI2cxNy02MScvPgo8dXNlIHg9JzE0MC43MjAxNTknIHk9JzY1Ljc2NjA0MicgeGxpbms6aHJlZj0nI2c3LTExNScvPgo8dXNlIHg9JzE1MC42MzY3NjcnIHk9JzYwLjcwMzE5NScgeGxpbms6aHJlZj0nI2cxMi01MCcvPgo8dXNlIHg9JzE1Ni4yOTU1ODQnIHk9JzY1Ljc2NjA0MicgeGxpbms6aHJlZj0nI2cxLTczJy8+CjwvZz4KPC9zdmc+) , and so this equation is validly/optimally (BLUE)
solved by OLSQ, giving instead
, and so this equation is validly/optimally (BLUE)
solved by OLSQ, giving instead ![\beta =
[\mathbf{X}^T\mathbf{R}^{-1}\mathbf{X}]^{-1}\,
\mathbf{X}^T\mathbf{R}^{-1} \mathbf{z}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuMi4xIC0tPgo8c3ZnIHZlcnNpb249JzEuMScgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluaycgd2lkdGg9JzE0Ny42NjkxODRwdCcgaGVpZ2h0PScxNS40ODc5MjVwdCcgdmlld0JveD0nNTYuNzQ2NzYxIDUzLjc1MjAxNSAxNDcuNjY5MTg0IDE1LjQ4NzkyNSc+CjxkZWZzPgo8dXNlIGlkPSdnMTctNDknIHhsaW5rOmhyZWY9JyNnNS00OScvPgo8cGF0aCBpZD0nZzUtNDknIGQ9J00yLjk5MjI5OC02Ljk1MTE4TDEuMTQxMzkyLTYuMDE1NDQ1Vi01Ljg3MTQ4NUMxLjI2NDc4Ni01LjkyMjg5OSAxLjM3Nzg5Ny01Ljk2NDAzMSAxLjQxOTAyOC01Ljk4NDU5NkMxLjYwNDExOS02LjA1NjU3NiAxLjc3ODkyNi02LjA5NzcwNyAxLjg4MTc1NC02LjA5NzcwN0MyLjA5NzY5My02LjA5NzcwNyAyLjE5MDIzOS01Ljk0MzQ2NSAyLjE5MDIzOS01LjYxNDQxNVYtLjk1NjMwMUMyLjE5MDIzOS0uNjE2OTY5IDIuMTA3OTc2LS4zODA0NjQgMS45NDM0NTEtLjI4NzkxOUMxLjc4OTIwOS0uMTk1MzczIDEuNjQ1MjUtLjE2NDUyNSAxLjIxMzM3Mi0uMTU0MjQyVjBINC4wNTE0MjhWLS4xNTQyNDJDMy4yMzkwODYtLjE2NDUyNSAzLjA3NDU2MS0uMjY3MzUzIDMuMDc0NTYxLS43NjA5MjhWLTYuOTMwNjE1TDIuOTkyMjk4LTYuOTUxMThaJy8+CjxwYXRoIGlkPSdnMy0wJyBkPSdNNi43NzYzNzMtMi4zNjUwNDdDNi45NTExOC0yLjM2NTA0NyA3LjEzNjI3MS0yLjM2NTA0NyA3LjEzNjI3MS0yLjU3MDcwM1M2Ljk1MTE4LTIuNzc2MzU5IDYuNzc2MzczLTIuNzc2MzU5SDEuMjEzMzcyQzEuMDM4NTY0LTIuNzc2MzU5IC44NTM0NzMtMi43NzYzNTkgLjg1MzQ3My0yLjU3MDcwM1MxLjAzODU2NC0yLjM2NTA0NyAxLjIxMzM3Mi0yLjM2NTA0N0g2Ljc3NjM3M1onLz4KPHBhdGggaWQ9J2cxMC04NCcgZD0nTTYuNTA5MDItNi43MTQ2NzZIMS4wMzg1NjRMLjYwNjY4Ni01LjEzMTEyM0wuNzkxNzc2LTUuMDg5OTkyQzEuMzM2NzY1LTYuMjAwNTM1IDEuNjY1ODE1LTYuMzc1MzQzIDMuMjM5MDg2LTYuMzU0Nzc3TDEuNzU4MzYxLS45MjU0NTNDMS41OTM4MzYtLjM4MDQ2NCAxLjM0NzA0OC0uMjE1OTM5IC42NjgzODMtLjE2NDUyNVYwSDMuNjUwMzk4Vi0uMTY0NTI1QzMuNDc1NTktLjE3NDgwOCAzLjMyMTM0OC0uMTk1MzczIDMuMjU5NjUxLS4xOTUzNzNDMi44NDgzMzktLjIyNjIyMiAyLjcyNDk0NS0uMzE4NzY3IDIuNzI0OTQ1LS42MjcyNTFDMi43MjQ5NDUtLjc2MDkyOCAyLjc1NTc5My0uODg0MzIyIDIuODQ4MzM5LTEuMjMzOTM3TDQuMjc3NjQ5LTYuMzU0Nzc3SDQuODQzMjA0QzUuNTgzNTY2LTYuMzU0Nzc3IDUuOTEyNjE2LTYuMDk3NzA3IDUuOTEyNjE2LTUuNTIxODdDNS45MTI2MTYtNS4zODgxOTMgNS45MDIzMzQtNS4yMzM5NTEgNS44ODE3NjgtNS4wNTkxNDNMNi4wNTY1NzYtNS4wMzg1NzdMNi41MDkwMi02LjcxNDY3NlonLz4KPHBhdGggaWQ9J2cxLTgyJyBkPSdNOS45MzUzNDUtLjM0NzM5QzkuNjg1MjI1LS4zNDczOSA5LjUwNDU4Mi0uNDMwNzYzIDkuMzY1NjI2LS42MTE0MDZMNi41NzI2MTMtNC41NzE2NDhDNy4zOTI0NTMtNC44MzU2NjUgNy43Mzk4NDItNS4wMTYzMDcgOC4xMjg5MTktNS4zNjM2OTdDOC41MzE4OTEtNS43Mzg4NzggOC43NTQyMi02LjI5NDcwMSA4Ljc1NDIyLTYuOTIwMDAzQzguNzU0MjItOC41MTc5OTUgNy4zNzg1NTctOS4zOTM0MTcgNC44MzU2NjUtOS4zOTM0MTdILjM2MTI4NVYtOS4wNDYwMjhDMS4zODk1NTktOC45NzY1NSAxLjU4NDA5Ny04Ljc2ODExNiAxLjU4NDA5Ny03Ljc2NzYzNFYtMS42MjU3ODRDMS41ODQwOTctLjYxMTQwNiAxLjQ0NTE0MS0uNDcyNDUgLjM2MTI4NS0uMzQ3MzlWMEg1LjA1Nzk5NFYtLjM0NzM5QzMuOTc0MTM4LS40ODYzNDYgMy44MzUxODItLjYzOTE5NyAzLjgzNTE4Mi0xLjYyNTc4NFYtNC4zNDkzMTlINC4yMTAzNjNMNy4wODY3NSAwSDkuOTM1MzQ1Vi0uMzQ3MzlaTTMuODM1MTgyLTguMzM3MzUzQzMuODM1MTgyLTguNDIwNzI2IDMuODkwNzY1LTguNjI5MTYgMy45MzI0NTEtOC43MTI1MzNDNC4wMTU4MjUtOC44NTE0ODkgNC4yMzgxNTQtOC45MjA5NjcgNC41ODU1NDQtOC45MjA5NjdDNS44NjM5MzgtOC45MjA5NjcgNi4zNzgwNzUtOC4zMjM0NTcgNi4zNzgwNzUtNi44NjQ0MkM2LjM3ODA3NS01Ljk3NTEwMyA2LjE2OTY0MS01LjQzMzE3NSA1LjcyNDk4Mi01LjE0MTM2N0M1LjM2MzY5Ny00LjkwNTE0MiA0Ljg5MTI0Ny00LjgwNzg3MyAzLjgzNTE4Mi00Ljc5Mzk3OFYtOC4zMzczNTNaJy8+CjxwYXRoIGlkPSdnMS04OCcgZD0nTTkuNTYwMTY0LTkuMzkzNDE3SDYuMDg2MjY3Vi05LjA0NjAyOEM2LjIxMTMyOC05LjAzMjEzMiA2LjMyMjQ5Mi05LjAzMjEzMiA2LjM2NDE3OS05LjAxODIzNkM2LjkyMDAwMy04Ljk5MDQ0NSA3LjA4Njc1LTguODY1Mzg1IDcuMDg2NzUtOC41MzE4OTFDNy4wODY3NS04LjI0MDA4MyA2LjkzMzg5OC03Ljk0ODI3NiA2LjI4MDgwNi03LjA1ODk1OUM2LjE2OTY0MS02LjkyMDAwMyA1Ljg1MDA0Mi02LjQ3NTM0NCA1LjUwMjY1My01Ljk4ODk5OEw0LjE1NDc4MS04LjA3MzMzNkMzLjk3NDEzOC04LjM1MTI0OCAzLjk0NjM0Ny04LjQyMDcyNiAzLjk0NjM0Ny04LjU4NzQ3M0MzLjk0NjM0Ny04Ljg3OTI4MSA0LjExMzA5NC04Ljk5MDQ0NSA0LjYxMzMzNS05LjAxODIzNkM0LjY4MjgxMy05LjAxODIzNiA0Ljg0OTU2LTkuMDMyMTMyIDUuMDQ0MDk4LTkuMDQ2MDI4Vi05LjM5MzQxN0guMjM2MjI1Vi05LjA0NjAyOEMuNzM2NDY2LTkuMDA0MzQxIC45MTcxMDktOC44NjUzODUgMS4zNDc4NzItOC4yNDAwODNMNC4wOTkxOTgtNC4xOTY0NjdMMS42Njc0NzEtMS4xMjU1NDNDMS4yNTA2MDMtLjYxMTQwNiAuOTE3MTA5LS40MzA3NjMgLjIyMjMyOS0uMzQ3MzlWMEgzLjY5NjIyNlYtLjM0NzM5QzIuODQ4NTk1LS40MzA3NjMgMi41NzA2ODQtLjU2OTcxOSAyLjU3MDY4NC0uOTE3MTA5QzIuNTcwNjg0LTEuMjIyODEyIDIuODQ4NTk1LTEuNjY3NDcxIDMuODc2ODY5LTMuMDU3MDI5TDQuNDA0OTAxLTMuNzY1NzA0TDUuODA4MzU2LTEuNTE0NjE5QzUuOTc1MTAzLTEuMjUwNjAzIDYuMTAwMTYzLS45MTcxMDkgNi4xMDAxNjMtLjc2NDI1N0M2LjEwMDE2My0uNTI4MDMyIDUuODYzOTM4LS40MDI5NzIgNS4zNzc1OTItLjM3NTE4MUM1LjMyMjAxLS4zNzUxODEgNS4xNjkxNTktLjM2MTI4NSA0Ljk4ODUxNi0uMzQ3MzlWMEg5LjcxMzAxNlYtLjM0NzM5QzkuMjQwNTY2LS4zNjEyODUgOS4wMzIxMzItLjU0MTkyOCA4LjM2NTE0NC0xLjU0MjQxTDUuODM2MTQ3LTUuNDc0ODYyTDYuOTQ3Nzk0LTcuMDE3MjcyQzguMTcwNjA2LTguNjg0NzQyIDguNTMxODkxLTguOTQ4NzU4IDkuNTYwMTY0LTkuMDQ2MDI4Vi05LjM5MzQxN1onLz4KPHBhdGggaWQ9J2cxLTEyMicgZD0nTTUuODM2MTQ3LTIuMjIzMjk0SDUuNDQ3MDdDNS4zMjIwMS0xLjc3ODYzNSA1LjIxMDg0NS0xLjUyODUxNSA0Ljk4ODUxNi0xLjIzNjcwN0M0LjU0Mzg1Ny0uNjI1MzAxIDQuMDg1MzAzLS40NDQ2NTkgMi45NzM2NTYtLjQ0NDY1OUgyLjU3MDY4NEw1Ljc4MDU2NC02LjA0NDU4MVYtNi40MDU4NjZILjYyNTMwMUwuNTI4MDMyLTQuNDMyNjkySC44ODkzMThDMS4yMzY3MDctNS43NTI3NzMgMS41OTc5OTMtNS45NzUxMDMgMy41NDMzNzUtNS45NjEyMDdMLjI5MTgwNy0uMzQ3MzlWMEg1LjYxMzgxN0w1LjgzNjE0Ny0yLjIyMzI5NFonLz4KPHVzZSBpZD0nZzIyLTYxJyB4bGluazpocmVmPScjZzE4LTYxJyB0cmFuc2Zvcm09J3NjYWxlKDEuMzUxMzQxKScvPgo8dXNlIGlkPSdnMjItOTEnIHhsaW5rOmhyZWY9JyNnMTgtOTEnIHRyYW5zZm9ybT0nc2NhbGUoMS4zNTEzNDEpJy8+Cjx1c2UgaWQ9J2cyMi05MycgeGxpbms6aHJlZj0nI2cxOC05MycgdHJhbnNmb3JtPSdzY2FsZSgxLjM1MTM0MSknLz4KPHVzZSBpZD0nZzEyLTk4JyB4bGluazpocmVmPScjZzgtOTgnIHRyYW5zZm9ybT0nc2NhbGUoMS4zNTEzNDEpJy8+CjxwYXRoIGlkPSdnMTgtNjEnIGQ9J003LjA2NDI5MS0zLjM2MjQ3OUM3LjIxODUzMy0zLjM2MjQ3OSA3LjQxMzkwNy0zLjM2MjQ3OSA3LjQxMzkwNy0zLjU2ODEzNVM3LjIxODUzMy0zLjc3Mzc5MiA3LjA3NDU3NC0zLjc3Mzc5MkguOTE1MTdDLjc3MTIxMS0zLjc3Mzc5MiAuNTc1ODM3LTMuNzczNzkyIC41NzU4MzctMy41NjgxMzVTLjc3MTIxMS0zLjM2MjQ3OSAuOTI1NDUzLTMuMzYyNDc5SDcuMDY0MjkxWk03LjA3NDU3NC0xLjM2NzYxNEM3LjIxODUzMy0xLjM2NzYxNCA3LjQxMzkwNy0xLjM2NzYxNCA3LjQxMzkwNy0xLjU3MzI3UzcuMjE4NTMzLTEuNzc4OTI2IDcuMDY0MjkxLTEuNzc4OTI2SC45MjU0NTNDLjc3MTIxMS0xLjc3ODkyNiAuNTc1ODM3LTEuNzc4OTI2IC41NzU4MzctMS41NzMyN1MuNzcxMjExLTEuMzY3NjE0IC45MTUxNy0xLjM2NzYxNEg3LjA3NDU3NFonLz4KPHBhdGggaWQ9J2cxOC05MScgZD0nTTIuNjIyMTE3IDIuNTcwNzAzVjIuMTU5MzlIMS42MjQ2ODRWLTcuMzAwNzk2SDIuNjIyMTE3Vi03LjcxMjEwOEgxLjIxMzM3MlYyLjU3MDcwM0gyLjYyMjExN1onLz4KPHBhdGggaWQ9J2cxOC05MycgZD0nTTEuNjM0OTY3LTcuNzEyMTA4SC4yMjYyMjJWLTcuMzAwNzk2SDEuMjIzNjU1VjIuMTU5MzlILjIyNjIyMlYyLjU3MDcwM0gxLjYzNDk2N1YtNy43MTIxMDhaJy8+CjxwYXRoIGlkPSdnOC05OCcgZD0nTS43MDk1MTQgLjYzNzUzNEMuNjE2OTY5IDEuMTgyNTIzIC40MTEzMTIgMS44OTIwMzcgLjI0Njc4NyAyLjI4Mjc4NEgxLjA4OTk3OEMxLjI2NDc4NiAyLjA0NjI3OSAxLjMzNjc2NSAxLjc2ODY0NCAxLjQ3MDQ0MiAuOTY2NTg0TDEuNzA2OTQ3LS40MzE4NzhDMi4xNzk5NTYtLjAyMDU2NiAyLjYxMTgzNCAuMTMzNjc3IDMuMjA4MjM3IC4xMzM2NzdDNC40MzE4OTIgLjEzMzY3NyA1LjQyOTMyNC0uNzcxMjExIDUuNjQ1MjYzLTIuMDk3NjkzQzUuODMwMzU0LTMuMTk3OTU0IDUuNDA4NzU5LTMuOTY5MTY1IDQuMzU5OTEyLTQuNDUyNDU3QzUuMjEzMzg1LTQuODc0MDUzIDUuNjY1ODI5LTUuMzQ3MDYyIDUuNzU4Mzc0LTUuOTMzMTgyQzUuOTEyNjE2LTYuODQ4MzUyIDUuMTMxMTIzLTcuNjA5MjggNC4wMzA4NjItNy42MDkyOEMyLjkyMDMxOC03LjYwOTI4IDEuOTY0MDE3LTYuODc5MjAxIDEuNzk5NDkyLTUuOTAyMzM0TC43MDk1MTQgLjYzNzUzNFpNMi42NDI2ODItNi4wMDUxNjJDMi43NTU3OTMtNi43MjQ5NTkgMy4yNjk5MzQtNy4yMjg4MTYgMy44NzY2Mi03LjIyODgxNkM0LjUyNDQzNy03LjIyODgxNiA0Ljg5NDYxOC02LjYzMjQxMyA0Ljc1MDY1OS01LjgwOTc4OEM0LjY2ODM5Ni01LjI2NDc5OSA0LjI3NzY0OS00LjY3ODY3OSA0LjAxMDI5Ni00LjY3ODY3OUMzLjk3OTQ0OC00LjY3ODY3OSAzLjk0ODYtNC42Nzg2NzkgMy43OTQzNTctNC43MTk4MUMzLjY0MDExNS00Ljc1MDY1OSAzLjU1Nzg1My00Ljc2MDk0MiAzLjQ3NTU5LTQuNzYwOTQyQzMuMjI4ODAzLTQuNzYwOTQyIDMuMDEyODY0LTQuNTk2NDE3IDIuOTcxNzMyLTQuNDAxMDQzQzIuOTQwODg0LTQuMjA1NjcgMy4xMDU0MDktNC4wODIyNzYgMy4zNzI3NjItNC4wODIyNzZDMy40MzQ0NTktNC4wODIyNzYgMy40ODU4NzMtNC4wOTI1NTkgMy41OTg5ODQtNC4xMTMxMjRDMy43MjIzNzgtNC4xNDM5NzMgMy44MjUyMDYtNC4xNTQyNTYgMy45MDc0NjgtNC4xNTQyNTZDNC4wNDExNDUtNC4xNTQyNTYgNC4xMTMxMjQtNC4xMzM2OSA0LjE2NDUzOS00LjA3MTk5M0M0LjU1NTI4NS0zLjY0MDExNSA0LjY5OTI0NS0yLjg1ODYyMiA0LjU2NTU2OC0yLjAxNTQzMUM0LjM5MDc2LS45ODcxNSAzLjgzNTQ4OS0uMzgwNDY0IDMuMDc0NTYxLS4zODA0NjRDMi41NjA0Mi0uMzgwNDY0IDIuMDg3NDExLS42MTY5NjkgMS44MDk3NzUtMS4wMTc5OThMMi42NDI2ODItNi4wMDUxNjJaJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PSc1Ni40MTMyNjcnIHk9JzY1Ljc2NjA0MicgeGxpbms6aHJlZj0nI2cxMi05OCcvPgo8dXNlIHg9JzY4Ljg4NTUzMycgeT0nNjUuNzY2MDQyJyB4bGluazpocmVmPScjZzIyLTYxJy8+Cjx1c2UgeD0nODIuODIyMjE0JyB5PSc2NS43NjYwNDInIHhsaW5rOmhyZWY9JyNnMjItOTEnLz4KPHVzZSB4PSc4Ni42ODU1ODUnIHk9JzY1Ljc2NjA0MicgeGxpbms6aHJlZj0nI2cxLTg4Jy8+Cjx1c2UgeD0nOTYuNzU1Nzg0JyB5PSc2MC43MDMxOTUnIHhsaW5rOmhyZWY9JyNnMTAtODQnLz4KPHVzZSB4PScxMDQuMzAzMjI2JyB5PSc2NS43NjYwNDInIHhsaW5rOmhyZWY9JyNnMS04MicvPgo8dXNlIHg9JzExNC4zNzM0MjQnIHk9JzYwLjcwMzE5NScgeGxpbms6aHJlZj0nI2czLTAnLz4KPHVzZSB4PScxMjIuMzkzMDI2JyB5PSc2MC43MDMxOTUnIHhsaW5rOmhyZWY9JyNnMTctNDknLz4KPHVzZSB4PScxMjguMDUxODM2JyB5PSc2NS43NjYwNDInIHhsaW5rOmhyZWY9JyNnMS04OCcvPgo8dXNlIHg9JzEzOC4xMjIwMzQnIHk9JzY1Ljc2NjA0MicgeGxpbms6aHJlZj0nI2cyMi05MycvPgo8dXNlIHg9JzE0MS45ODU0MDYnIHk9JzYwLjcwMzE5NScgeGxpbms6aHJlZj0nI2czLTAnLz4KPHVzZSB4PScxNTAuMDA1MDA4JyB5PSc2MC43MDMxOTUnIHhsaW5rOmhyZWY9JyNnMTctNDknLz4KPHVzZSB4PScxNTcuMjEzNTQ4JyB5PSc2NS43NjYwNDInIHhsaW5rOmhyZWY9JyNnMS04OCcvPgo8dXNlIHg9JzE2Ny4yODM3NDYnIHk9JzYwLjcwMzE5NScgeGxpbms6aHJlZj0nI2cxMC04NCcvPgo8dXNlIHg9JzE3NC44MzExODgnIHk9JzY1Ljc2NjA0MicgeGxpbms6aHJlZj0nI2cxLTgyJy8+Cjx1c2UgeD0nMTg0LjkwMTM4NicgeT0nNjAuNzAzMTk1JyB4bGluazpocmVmPScjZzMtMCcvPgo8dXNlIHg9JzE5Mi45MjA5ODgnIHk9JzYwLjcwMzE5NScgeGxpbms6aHJlZj0nI2cxNy00OScvPgo8dXNlIHg9JzE5OC41Nzk3OTgnIHk9JzY1Ljc2NjA0MicgeGxpbms6aHJlZj0nI2cxLTEyMicvPgo8L2c+Cjwvc3ZnPg==) . The actual calculations in
3dREMLfit are a little more intricate for the sake of efficiency and
require estimating (using
. The actual calculations in
3dREMLfit are a little more intricate for the sake of efficiency and
require estimating (using  ) and
together to be self consistent – that’s the point of
REML. See the aforementioned math notes for more such “fun”.
) and
together to be self consistent – that’s the point of
REML. See the aforementioned math notes for more such “fun”.
Trying it out:
The simplest way to deal with the initial question was to run the
program both ways. To aid in doing this, I modified 3dDeconvolve
to allow the user (me) to generate the matrix file for 3dREMLfit
with censoring handled by column augmentation, in addition to the
matrix created with row removal. (3dDeconvolve creates the matrix
file for 3dREMLfit, from the user’s time series model components.)
3dREMLfit could then be run twice, once with each censoring
method. I used a study which had already been run with
afni_proc.py, and started from that results directory.
Script 1: create the two
*.xmat.1Dfiles (
matrices) in 3dDeconvolveThis command was edited from the script generated byafni_proc.py:3dDeconvolve \ -input pb01.sub-10697.r01.tshift+orig.HEAD \ -censor censor_sub-10697_combined_2.1D \ -polort 4 -num_stimts 8 \ -stim_times 1 stimuli/pamenc.times.CONTROL.txt 'BLOCK(2)' \ -stim_label 1 CONTROL \ -stim_times 2 stimuli/pamenc.times.TASK.txt 'BLOCK(4)' \ -stim_label 2 TASK \ -stim_file 3 'motion_demean.1D[0]' -stim_base 3 -stim_label 3 roll \ -stim_file 4 'motion_demean.1D[1]' -stim_base 4 -stim_label 4 pitch \ -stim_file 5 'motion_demean.1D[2]' -stim_base 5 -stim_label 5 yaw \ -stim_file 6 'motion_demean.1D[3]' -stim_base 6 -stim_label 6 dS \ -stim_file 7 'motion_demean.1D[4]' -stim_base 7 -stim_label 7 dL \ -stim_file 8 'motion_demean.1D[5]' -stim_base 8 -stim_label 8 dP \ -x1D XQ.xmat.1D \ -x1D_regcensored XQ.regcensor.xmat.1D \ -x1D_stopThe
-x1D ..and-x1D_regcensored ..options lead to outputting the two*.xmat.1Dfiles for input to3dREMLfit(row-censored and column-augmented).Script 2: run
3dREMLfittwice, using the two matrix files, on the time-shifted input data:3dREMLfit \ -matrix XQ.xmat.1D \ -input pb01.sub-10697.r01.tshift+orig.HEAD \ -fout -tout -verb -Grid 5 \ -Rbuck QQstats.sub-10697_REML \ -Rvar QQstats.sub-10697_REMLvar 3dREMLfit \ -matrix XQ.regcensor.xmat.1D \ -input pb01.sub-10697.r01.tshift+orig.HEAD \ -fout -tout -verb -Grid 5 \ -Rbuck QQRstats.sub-10697_REML \ -Rvar QQRstats.sub-10697_REMLvar
... and then the stats datasets from the two runs can be compared (visually and by subtraction).
It turned out that the results were exactly the same, except in a few voxels – about 10 out of more than 300,000. This outcome was peculiar, but a few moments of inspection showed that the differences occurred precisely in those (non-brain) voxels which were identically 0 except at one or more of the censored time points. When I realized this, the explanation was obvious.
With row removal, the censored data points are fully removed from the
analysis. In these exceptional voxels, that removal resulted in the
data time series being identically zero. When this
happens, 3dREMLfit skips all analysis in that voxel, and fills in
the corresponding voxel results as being all zeros. In column
augmentation, normal linear solving will take place, as the data is
not exactly zero. In exact arithmetic solution, the augmented columns
would zero out the nonzero elements of ; however,
with inexact computer arithmetic, the linear regression leaves a
nonzero residual vector , which in turn is analyzed
for the ARMA(1,1) parameters, and then and all the
voxel-level statistics are calculated. Question answered:
3dREMLfit works the same for either censoring method.
But ... there’s always a “but”:
In looking at the results from Script 2, I saw something peculiar:
Structure in the |
|---|
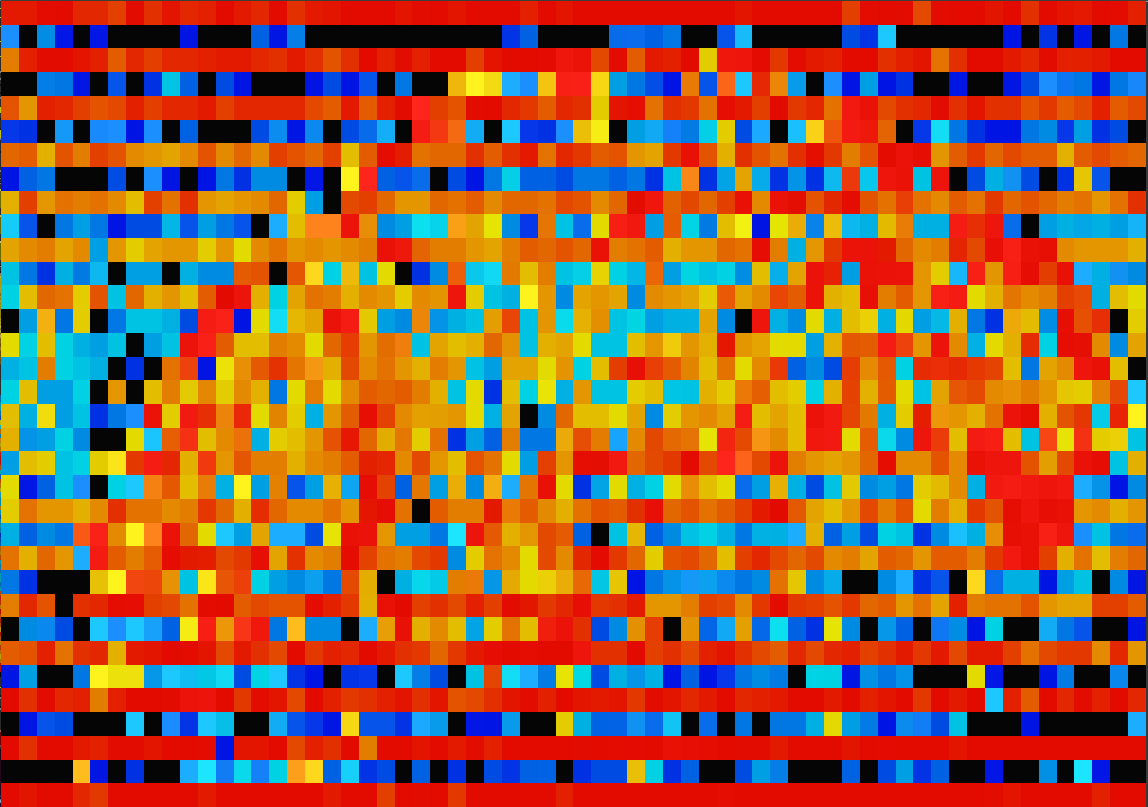
|
Output from |
This is an image of the  parameter = correlation at
lag=1 from the ARMA(1,1) model. A little thought shows that this is
due to the time-shifting operation. By default, the necessary temporal
interpolation is done with 5th order (quintic) Lagrange polynomials,
which uses
parameter = correlation at
lag=1 from the ARMA(1,1) model. A little thought shows that this is
due to the time-shifting operation. By default, the necessary temporal
interpolation is done with 5th order (quintic) Lagrange polynomials,
which uses  points in time for interpolation (via AFNI
program
points in time for interpolation (via AFNI
program 3dTshift). I re-ran the time shifting with the various
options for interpolation method, and found that the Fourier (FFT)
interpolation completely eliminated the stripes. To further
investigate, I added  and
and  point weighted sinc
interpolation methods to 3dTshift. The striping artifact is reduced
with the “wsinc5” method, and almost completely gone with the “wsinc9”
method.
point weighted sinc
interpolation methods to 3dTshift. The striping artifact is reduced
with the “wsinc5” method, and almost completely gone with the “wsinc9”
method.
How important is this artifact? If one is using 3dREMLfit, then
the voxelwise ARMA(1,1) model should deal with it. The alternative
cure, using a broader-based temporal interpolation, gets rid of the
artifact, but has the downside that more distant time points will leak
into the interpolated output values. In turn, this could bias the
estimation – probably not much, but that is another line
for investigation.
Conclusion: The Rabbit Hole Has No Bottom.
9.8.3. Attributes in the 3dREMLFIT *.xmat.1D format¶
Attributes are stored in an XML-ish header before the actual matrix
numbers. Attributes are of the form name = "quoted string" - the
quotes can be single or double.
Below is a sample header, followed by the first row of the matrix (there are 444 rows in the actual matrix, each with 20 numbers):
1# <matrix
2# ni_type = "20*double"
3# ni_dimen = "444"
4# ColumnLabels = "Run#1Pol#0 ; Run#1Pol#1 ; Run#1Pol#2 ; Run#1Pol#3 ; Run#2Pol#0 ; Run#2Pol#1 ; Run#2Pol#2 ; Run#2Pol#3 ; Run#3Pol#0 ; Run#3Pol#1 ; Run#3Pol#2 ; Run#3Pol#3 ; vis#0 ; aud#0 ; roll#0 ; pitch#0 ; yaw#0 ; dS#0 ; dL#0 ; dP#0"
5# ColumnGroups = "12@-1,1,2,6@0"
6# RowTR = "2"
7# GoodList = "0..40,45..264,267..449"
8# NRowFull = "450"
9# RunStart = "0,150,300"
10# Nstim = "2"
11# StimBots = "12,13"
12# StimTops = "12,13"
13# StimLabels = "vis ; aud"
14# Nglt = "1"
15# GltLabels = "V-A"
16# GltMatrix_000000 = "1,20,12@0,1,-1,6@0"
17# BasisNstim = "8"
18# BasisOption_000001 = "-stim_times"
19# BasisName_000001 = "vis"
20# BasisFormula_000001 = "BLOCK(20,1)"
21# BasisColumns_000001 = "12:12"
22# BasisOption_000002 = "-stim_times"
23# BasisName_000002 = "aud"
24# BasisFormula_000002 = "BLOCK(20,1)"
25# BasisColumns_000002 = "13:13"
26# CommandLine = "3dDeconvolve -input pb05.FT.surf.rh.r01.scale.niml.dset pb05.FT.surf.rh.r02.scale.niml.dset pb05.FT.surf.rh.r03.scale.niml.dset -censor motion_FT.surf_censor.1D -polort 3 -num_stimts 8 -stim_times 1 stimuli/AV1_vis.txt 'BLOCK(20,1)' -stim_label 1 vis -stim_times 2 stimuli/AV2_aud.txt 'BLOCK(20,1)' -stim_label 2 aud -stim_file 3 'motion_demean.1D[0]' -stim_base 3 -stim_label 3 roll -stim_file 4 'motion_demean.1D[1]' -stim_base 4 -stim_label 4 pitch -stim_file 5 'motion_demean.1D[2]' -stim_base 5 -stim_label 5 yaw -stim_file 6 'motion_demean.1D[3]' -stim_base 6 -stim_label 6 dS -stim_file 7 'motion_demean.1D[4]' -stim_base 7 -stim_label 7 dL -stim_file 8 'motion_demean.1D[5]' -stim_base 8 -stim_label 8 dP -jobs 2 -gltsym 'SYM: vis -aud' -glt_label 1 V-A -fout -tout -x1D X.xmat.1D -xjpeg X.jpg -x1D_uncensored X.nocensor.xmat.1D -fitts fitts.FT.surf.rh.niml.dset -errts errts.FT.surf.rh.niml.dset -bucket stats.FT.surf.rh.niml.dset"
27# >
281 -0.99999999284744 0.9932885915041 -1.0000000007947 0 0 0 0 0 0 0 0 0 0 -0.056317329311536 0.1472171255615 -0.030924689328919 -0.14155002441671 -0.0522833100934 -0.081843944456843
For computational details, idly peruse this scan of my handwritten notes about 3dREMLfit’s algorithms and models:
Some attributes are necessary for 3dREMLfit to operate, and some are
optional. The leading '#' character on each line is not necessary,
and is there for peculiar historical/hysterical reasons and also for
compatibility with some other AFNI software (e.g., 1dplot).
Attributes can be in any order inside the <matrix ... > header.
Note that index counting (e.g., for rows and columns, mentioned below) starts at 0, not 1, as decreed by the Almighty.
ni_type = "20*double"[REQUIRED]
This indicates there are 20 numerical values per row in the data section (past the header), and they are to be interpreted as doubles (64 bit floating point values) when read in.
In this example, the matrix has 20 columns (regressors) – numbered from 0..19, as mentioned above.
In the code, this numeric value (20) is called nreg = number of regressors; that is how I will refer to it below, as needed.
The
"*double"is needed, since the parser for this format allows data columns of various types, but in this case all the data columns are numeric.
ni_dimen = "444"[REQUIRED]
This value indicates there are 444 rows in the data section.
In this example, the matrix corresponds to 444 time points (TRs).
Also see
NRowFullbelow.
ColumnLabels = "Run#1Pol#0 ; Run#1Pol#1 ; Run#1Pol#2 ; Run#1Pol#3 ; Run#2Pol#0 ; Run#2Pol#1 ; Run#2Pol#2 ; Run#2Pol#3 ; Run#3Pol#0 ; Run#3Pol#1 ; Run#3Pol#2 ; Run#3Pol#3 ; vis#0 ; aud#0 ; roll#0 ; pitch#0 ; yaw#0 ; dS#0 ; dL#0 ; dP#0"[OPTIONAL but highly recommended]
Defines the string label for each column in the matrix.
If this attribute is present, there must be as many labels as columns (nreg).
Labels cannot contain whitespace characters unless ‘in quotes’.
In this example, single quotes would have to be used, to distinguish from the double quotes used to delineate the attribute itself.
Labels must be separated as shown above, with a semicolon (labels can contain commas, if you insist).
In this example, columns 0..11 and 14..19 are regressors of no interest, and columns 12 and 13 (
vis#0andaud#0) are the regressors of interest (response models for stimuli).Which regressors correspond to stimuli and which do not will be marked out in the
'Stim'attributes described later.
Labels are attached to output volumes in the results datasets, to make it easy for the AFNI user to see which volume corresponds to the statistical estimates for which stimulus.
ColumnGroups = "12@-1,1,2,6@0"[NOT USED]
This attribute is not actually used by
3dREMLfitfor anything at this time [Aug 2019].Its intended function is to mark matrix columns as being in different groups. In this example, the first 12 columns are “baseline and drift model” (group -1), the next 2 columns belong to distinct stimuli, and the last 6 columns belong to the motion regressors (and other dataset-based) regressors of no interest.
RowTR = "2"[OPTIONAL]
This attribute is not actually used by
3dREMLfitnow [Aug 2019].It defines the inter-scan time interval (TR) in seconds. The TR is needed for construction of the matrix from the stimulus response model, but that has already been done, so this attribute is really just for documentation and completeness.
GoodList = "0..40,45..264,267..449"[HIGHLY REQUIRED]
The matrix provided to
3dREMLfitis the censored matrix; that is, the time points (TRs) to be censored have had the corresponding rows removed from the full matrix.The data volumes to be censored will be removed from the input dataset during processing by
3dREMLfit.
The
GoodListattribute lists the TR indexes from the original (uncensored) time series dataset that are present in the matrix file; that is, it is the opposite of the “censor list”.There must be the same number of integers specified here as the number of time points specified by the
ni_dimenattribute (here, 444).The brute force approach would be just to list all the integers, comma separated, in one long string.
For the sake of compactness, contiguous sequences of integers can be given, as in the example, where
"0..40"means the same as listing all the integers 0, 1, 2, ..., 40.In this example, there were 450 time points in the original EPI dataset, and clearly 6 of them have been censored, since the matrix has only 444 rows.
This attribute is required so that the temporal autocorrelation ARMA(1,1) voxelwise model doesn’t falsely assume that the data to be processed occurs with constant TR.
The RunStart attribute (below) subserves this purpose also, marking the temporal discontinuities between multiple EPI imaging runs.
If there were no censoring, then
GoodList = "0..449"would work fine (but still would be required by3dREMLfit).
NRowFull = "450"[REQUIRED]
This attribute gives the number of TRs in the full (uncensored matrix).
It is needed for creating the “fitts” and “errts” output datasets, and also for consistency checking to make sure that the user is inputting data that matches the matrix.
RunStart = "0,150,300"[OPTIONAL]
If there is more than one imaging run – that is, there is a long temporal discontinuity between some time points in the dataset to be processed – then this attribute gives the list of the starting TR indexes for each run.
In this example, there were 3 runs of 150 TRs each: 0..149, 150..299, and 300..499.
The ARMA(1,1) model for the noise temporal correlation is built to have zero correlations for time point pairs from different runs; see the math notes for details on how this is implemented.
As with
GoodList, this attribute is needed for correct temporal autocorrelation model fitting.If
RunStartis not present, then the input EPI dataset is presumed to contain only one imaging run.
The
"Stim"group of attributes mark off some columns as being “of interest” for statistics – presumably from task stimuli. These are [OPTIONAL] as a group, but ifNstimis present, then the others must be present as well.Statistics (betas and t-statistics) will be computed only for columns marked as belonging to stimuli, since no one is ever interested in the statistics for the drift and motion parameters (e.g.). If the
"Stim"attributes are not present, statistics will not be calculated unless GLTs are used.Nstim = "2"This attribute indicates how many distinct stimuli present.
Each stimulus will correspond to 1 or more contiguous columns in the matrix.
StimBots = "12,13"This attribute should have
Nstiminteger entries.It indicates the column indexes (remember, counting starts at 0) that correspond to the start of each stimulus’s column group.
StimTops = "12,13"This attribute should have
Nstiminteger entries.It indicates the column indexes that correspond to the end of each stimulus’s column group.
In this example, the model for each stimulus has just one column, so the
StimBotsandStimTopsattributes are identical.In deconvolution type models (e.g., AFNI
TENTS, FIR models) or in parametric regression, a single stimulus will have multiple regression columns in its response model.
StimLabels = "vis ; aud"This attribute should have Nstim string entries, separated by semicolons.
These are used (among other things) to process symbolic general linear tests (GLTs) among beta coefficients, given on the
3dREMLfitcommand line via the"-gltsym"option.
The “GLT” group is used to specify one or more general linear tests among the beta coefficients, directly in the matrix file. These are completely [OPTIONAL].
As mentioned above, GLTs can also be specified outside the matrix file, on the
3dREMLfitcommand line.GLTs in the matrix file are specified as sets of coefficients to be applied to the beta estimates.
GLTs on the
3dREMLfitcommand line can use symbolic names for the stimuli to specify the coefficients to be attached to the betas.
Nglt = "1"If present, this attribute specifies the number of GLTs in the matrix file. It should be an integer from 1 to 1000000.
GltLabels = "V-A"This attribute contains Nglt string labels, one for each GLT specified.
The labels are attached to the output data volumes to make it easy for the user to see which volume corresponds to what statistical test.
GltMatrix_000000 = "1,20,12@0,1,-1,6@0"There should be
Ngltof these attributes, with a six digit suffix starting at_000000, then_000001, and so forth. (If you want more than 1 million GLTs, you are legally insane and should be confined for your own safety.)Each
GltMatrix_xxxxxxattribute hasr*nreg+2numeric values, which are used to define an matrix for some
matrix for some  .
.The first value in the attribute is the number of rows r in the GLT matrix.
r = 1corresponds to a t-test of the weighted sum of betas against the null hypothesis that the sum is 0.r > 1corresponds to an F-test of the r weighted beta sums defined by the individual rows against the null hypothesis that these sums are all zero.
The second value in the attribute is the number of columns in the GLT matrix.
This value must be the same as nreg, or
3dREMLfitwill not like the matrix file (i.e., it will exit with an error message). It is present here to make the matrix definition self-contained, and as a check that the creator of the matrix file is not deranged.
The remaining values are the rows of the GLT matrix, nreg numbers per row, r rows, row after row.
In the example, there are only 2 nonzero numbers in the single row, corresponding (naturally) to the test
vis-aud≟0.There is no requirement that a GLT be a “contrast”; that is, the sum of the weights in the rows do not need to be 0.
The “Basis” group of attributes is [NOT USED] by 3dREMLfit at this time.
I won't describe them now, since this exercise is really getting dull.
Their function is to describe the response model used to construct the stimulus columns, and the example above is from AFNI program
3dDeconvolve.
I don’t even recall why I put this stuff in here (for Rick Reynolds, maybe?).
CommandLine = "3dDeconvolve -input ......"[OPTIONAL]
This option is used to write the command that generated the matrix file into the output dataset(s) history note, for the potential elucidation of any user of the data. Otherwise, it is not needed or used.
