7.2. 1dDW_Grad_o_Mat++: dealing with DW gradients¶
7.2.1. Overview¶
In diffusion weighted imaging (DWI), magnetic field gradients are applied along various spatial directions to probe relative diffusivity along different orientations. In order to estimate the diffusion tensor (DT), we need to have a recording of what was the directionality of each gradient (g, a vector of unit length), and what was the strength of the extra magnetic field (b, a scalar) was used.
Many different programs and software, starting from the MRI machines themselves, use different notations and methods of reading and writing the gradient direction and strength information. Drat. Therefore, there is some need for manipulating them during the analysis process (sometimes even iteratively to make sure that everything matches).
Since each gradient and b-value have a one-to-one correspondence with an acquired DWI volume, we would also like to keep the processing of any one type of data in line with the others. For example, common DWI processing includes averaging the b=0 reference images together, and possibly averaging repetitions of sets of DWIs together (in both cases, to have higher SNR of individual datasets)– programs discussed here allow one to semi-automate these averaging processes (as well as check that averaging is really feasible) while appropriately updating gradient information.
Note
Below, when referring to DW factors, the assumed units of
the b-values are always:  (unless
otherwise stated.
(unless
otherwise stated.
Diffusion gradients¶
The spatial orientations of the applied diffusion weighting gradients are typically recorded as unit normal vectors, which can be expressed as (equivalently, just with different notations):

where  for DWIs, and
for DWIs, and  for the b=0 reference images. For example, a
diffusion gradient applied entirely in the from ‘top’ to ‘bottom’ in
the z-direction (of whatever set of axes the scanner is using)
might be expressed as (0, 0, 1), and one purely in the xy-plane
could be (0.707, -0.707, 0) or (-0.950, -0.436, 0), etc.
for the b=0 reference images. For example, a
diffusion gradient applied entirely in the from ‘top’ to ‘bottom’ in
the z-direction (of whatever set of axes the scanner is using)
might be expressed as (0, 0, 1), and one purely in the xy-plane
could be (0.707, -0.707, 0) or (-0.950, -0.436, 0), etc.
Note
Sometimes the ‘reference’ images aren’t exactly totally unweighed with b=0. Some data acquisition protocols use a magnetic field gradient with a small DW factor, such as b=5, as a reference volume. Such data can be processed here, one just needs to include the b value information explicitly and specify below what DW factor are reference values.
The gradient information is often saved in a text file as three rows
of numbers (for example, the *.bvecs files created by
dcm2niix) or as three columns. If the acquisition contained N
reference (b=0) images and M DWIs, then these initial files
typically have dimensionality  or
or
 , respectively. Additionally, a separate file
may contain the list of DW factors (i.e., the b-values), and there
would be
, respectively. Additionally, a separate file
may contain the list of DW factors (i.e., the b-values), and there
would be  in a single row or column.
in a single row or column.
Diffusion matrices¶
The directionality diffusion gradients may also be encoded as a
 matrix:
matrix:
![\mathbf{G}=
\left[\begin{array}{ccc}
G_{xx}&G_{xy}&G_{xz}\\
G_{yx}&G_{yy}&G_{yz}\\
G_{zx}&G_{zy}&G_{zz}
\end{array}\right],~~~{\rm or}~~~
\left[\begin{array}{ccc}
G_{11}&G_{12}&G_{13}\\
G_{21}&G_{22}&G_{23}\\
G_{31}&G_{32}&G_{33}
\end{array}\right].](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuMi4xIC0tPgo8c3ZnIHZlcnNpb249JzEuMScgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluaycgd2lkdGg9JzI5MS4wMDA3ODVwdCcgaGVpZ2h0PSc1MC4wNzU5OTRwdCcgdmlld0JveD0nODcuMjg0NzU1IDc5LjAxOTc0NyAyOTEuMDAwNzg1IDUwLjA3NTk5NCc+CjxkZWZzPgo8dXNlIGlkPSdnMjEtMTExJyB4bGluazpocmVmPScjZzE3LTExMScgdHJhbnNmb3JtPSdzY2FsZSgxLjM1MTM0MSknLz4KPHVzZSBpZD0nZzIxLTExNCcgeGxpbms6aHJlZj0nI2cxNy0xMTQnIHRyYW5zZm9ybT0nc2NhbGUoMS4zNTEzNDEpJy8+Cjx1c2UgaWQ9J2cxMy01OCcgeGxpbms6aHJlZj0nI2c5LTU4JyB0cmFuc2Zvcm09J3NjYWxlKDEuMzUxMzQxKScvPgo8dXNlIGlkPSdnMTMtNTknIHhsaW5rOmhyZWY9JyNnOS01OScgdHJhbnNmb3JtPSdzY2FsZSgxLjM1MTM0MSknLz4KPHBhdGggaWQ9J2czLTUwJyBkPSdNNC41Mjk5NjIgMjQuNDU2MjM0SDUuNDg4NzU3Vi40MTY4NjhIOS4xNTcxOTJWLS41NDE5MjhINC41Mjk5NjJWMjQuNDU2MjM0WicvPgo8cGF0aCBpZD0nZzMtNTEnIGQ9J00zLjc2NTcwNCAyNC40NTYyMzRINC43MjQ1Vi0uNTQxOTI4SC4wOTcyNjlWLjQxNjg2OEgzLjc2NTcwNFYyNC40NTYyMzRaJy8+CjxwYXRoIGlkPSdnMy01MicgZD0nTTQuNTI5OTYyIDI0LjQ0MjMzOUg5LjE1NzE5MlYyMy40ODM1NDNINS40ODg3NTdWLS41NTU4MjRINC41Mjk5NjJWMjQuNDQyMzM5WicvPgo8cGF0aCBpZD0nZzMtNTMnIGQ9J00zLjc2NTcwNCAyMy40ODM1NDNILjA5NzI2OVYyNC40NDIzMzlINC43MjQ1Vi0uNTU1ODI0SDMuNzY1NzA0VjIzLjQ4MzU0M1onLz4KPHVzZSBpZD0nZzIyLTYxJyB4bGluazpocmVmPScjZzE4LTYxJyB0cmFuc2Zvcm09J3NjYWxlKDEuMzUxMzQxKScvPgo8cGF0aCBpZD0nZzE3LTQ5JyBkPSdNMi45OTIyOTgtNi45NTExOEwxLjE0MTM5Mi02LjAxNTQ0NVYtNS44NzE0ODVDMS4yNjQ3ODYtNS45MjI4OTkgMS4zNzc4OTctNS45NjQwMzEgMS40MTkwMjgtNS45ODQ1OTZDMS42MDQxMTktNi4wNTY1NzYgMS43Nzg5MjYtNi4wOTc3MDcgMS44ODE3NTQtNi4wOTc3MDdDMi4wOTc2OTMtNi4wOTc3MDcgMi4xOTAyMzktNS45NDM0NjUgMi4xOTAyMzktNS42MTQ0MTVWLS45NTYzMDFDMi4xOTAyMzktLjYxNjk2OSAyLjEwNzk3Ni0uMzgwNDY0IDEuOTQzNDUxLS4yODc5MTlDMS43ODkyMDktLjE5NTM3MyAxLjY0NTI1LS4xNjQ1MjUgMS4yMTMzNzItLjE1NDI0MlYwSDQuMDUxNDI4Vi0uMTU0MjQyQzMuMjM5MDg2LS4xNjQ1MjUgMy4wNzQ1NjEtLjI2NzM1MyAzLjA3NDU2MS0uNzYwOTI4Vi02LjkzMDYxNUwyLjk5MjI5OC02Ljk1MTE4WicvPgo8cGF0aCBpZD0nZzE3LTUwJyBkPSdNNC44ODQzMzUtMS40MDg3NDVMNC43NTA2NTktMS40NjAxNTlDNC4zNzAxOTUtLjg3NDAzOSA0LjIzNjUxOC0uNzgxNDk0IDMuNzczNzkyLS43ODE0OTRIMS4zMTYyTDMuMDQzNzEyLTIuNTkxMjY4QzMuOTU4ODgyLTMuNTQ3NTcgNC4zNTk5MTItNC4zMjkwNjQgNC4zNTk5MTItNS4xMzExMjNDNC4zNTk5MTItNi4xNTk0MDQgMy41MjcwMDQtNi45NTExOCAyLjQ1NzU5Mi02Ljk1MTE4QzEuODkyMDM3LTYuOTUxMTggMS4zNTczMzEtNi43MjQ5NTkgLjk3Njg2Ny02LjMxMzY0NkMuNjQ3ODE3LTUuOTY0MDMxIC40OTM1NzUtNS42MzQ5ODEgLjMxODc2Ny00LjkwNDkwMUwuNTM0NzA2LTQuODUzNDg3Qy45NDYwMTktNS44NjEyMDIgMS4zMTYyLTYuMTkwMjUyIDIuMDI1NzE0LTYuMTkwMjUyQzIuODg5NDctNi4xOTAyNTIgMy40NzU1OS01LjYwNDEzMiAzLjQ3NTU5LTQuNzQwMzc2QzMuNDc1NTktMy45MzgzMTcgMy4wMDI1ODEtMi45ODIwMTUgMi4xMzg4MjUtMi4wNjY4NDVMLjMwODQ4NC0uMTIzMzk0VjBINC4zMTg3ODFMNC44ODQzMzUtMS40MDg3NDVaJy8+CjxwYXRoIGlkPSdnMTctNTEnIGQ9J00xLjU3MzI3LTMuMzkzMzI4QzIuMTc5OTU2LTMuMzkzMzI4IDIuNDE2NDYxLTMuMzcyNzYyIDIuNjYzMjQ4LTMuMjgwMjE3QzMuMzAwNzgyLTMuMDUzOTk1IDMuNzAxODEyLTIuNDY3ODc1IDMuNzAxODEyLTEuNzU4MzYxQzMuNzAxODEyLS44OTQ2MDUgMy4xMTU2OTItLjIyNjIyMiAyLjM1NDc2NC0uMjI2MjIyQzIuMDc3MTI4LS4yMjYyMjIgMS44NzE0NzItLjI5ODIwMiAxLjQ5MTAwOC0uNTQ0OTg5QzEuMTgyNTIzLS43MzAwOCAxLjAwNzcxNS0uODAyMDU5IC44MzI5MDgtLjgwMjA1OUMuNTk2NDAzLS44MDIwNTkgLjQ0MjE2MS0uNjU4MSAuNDQyMTYxLS40NDIxNjFDLjQ0MjE2MS0uMDgyMjYyIC44ODQzMjIgLjE0Mzk1OSAxLjYwNDExOSAuMTQzOTU5QzIuMzk1ODk1IC4xNDM5NTkgMy4yMDgyMzctLjEyMzM5NCAzLjY5MTUyOS0uNTQ0OTg5UzQuNDQyMTc0LTEuNTYyOTg3IDQuNDQyMTc0LTIuMjUxOTM2QzQuNDQyMTc0LTIuNzc2MzU5IDQuMjc3NjQ5LTMuMjU5NjUxIDMuOTc5NDQ4LTMuNTc4NDE4QzMuNzczNzkyLTMuODA0NjQgMy41Nzg0MTgtMy45MjgwMzQgMy4xMjU5NzUtNC4xMjM0MDdDMy44MzU0ODktNC42MDY2OTkgNC4wOTI1NTktNC45ODcxNjMgNC4wOTI1NTktNS41NDI0MzVDNC4wOTI1NTktNi4zNzUzNDMgMy40MzQ0NTktNi45NTExOCAyLjQ4ODQ0LTYuOTUxMThDMS45NzQzLTYuOTUxMTggMS41MjE4NTYtNi43NzYzNzMgMS4xNTE2NzUtNi40NDczMjNDLjg0MzE5MS02LjE2OTY4NyAuNjg4OTQ4LTUuOTAyMzM0IC40NjI3MjctNS4yODUzNjVMLjYxNjk2OS01LjI0NDIzNEMxLjAzODU2NC01Ljk5NDg3OSAxLjUwMTI5LTYuMzM0MjEyIDIuMTQ5MTA4LTYuMzM0MjEyQzIuODE3NDktNi4zMzQyMTIgMy4yODAyMTctNS44ODE3NjggMy4yODAyMTctNS4yMzM5NTFDMy4yODAyMTctNC44NjM3NyAzLjEyNTk3NS00LjQ5MzU4OSAyLjg2ODkwNC00LjIzNjUxOEMyLjU2MDQyLTMuOTI4MDM0IDIuMjcyNTAxLTMuNzczNzkyIDEuNTczMjctMy41MjcwMDRWLTMuMzkzMzI4WicvPgo8cGF0aCBpZD0nZzE3LTExMScgZD0nTTIuNTcwNzAzLTQuNzMwMDkzQzEuMjMzOTM3LTQuNzMwMDkzIC4yOTgyMDItMy43NDI5NDMgLjI5ODIwMi0yLjMyMzkxNUMuMjk4MjAyLS45MzU3MzYgMS4yNTQ1MDMgLjEwMjgyOCAyLjU1MDEzNyAuMTAyODI4UzQuODMyOTIxLS45ODcxNSA0LjgzMjkyMS0yLjQwNjE3OEM0LjgzMjkyMS0zLjc1MzIyNiAzLjg4NjkwMy00LjczMDA5MyAyLjU3MDcwMy00LjczMDA5M1pNMi40MzcwMjYtNC40NDIxNzRDMy4zMDA3ODItNC40NDIxNzQgMy45MDc0NjgtMy40NTUwMjUgMy45MDc0NjgtMi4wNDYyNzlDMy45MDc0NjgtLjg4NDMyMiAzLjQ0NDc0Mi0uMTg1MDkxIDIuNjczNTMxLS4xODUwOTFDMi4yNzI1MDEtLjE4NTA5MSAxLjg5MjAzNy0uNDMxODc4IDEuNjc2MDk4LS44NDMxOTFDMS4zODgxOC0xLjM3Nzg5NyAxLjIyMzY1NS0yLjA5NzY5MyAxLjIyMzY1NS0yLjgyNzc3M0MxLjIyMzY1NS0zLjgwNDY0IDEuNzA2OTQ3LTQuNDQyMTc0IDIuNDM3MDI2LTQuNDQyMTc0WicvPgo8cGF0aCBpZD0nZzE3LTExNCcgZD0nTS4wNzE5OC00LjAxMDI5NkMuMjE1OTM5LTQuMDQxMTQ1IC4zMDg0ODQtNC4wNTE0MjggLjQzMTg3OC00LjA1MTQyOEMuNjg4OTQ4LTQuMDUxNDI4IC43ODE0OTQtMy44ODY5MDMgLjc4MTQ5NC0zLjQzNDQ1OVYtLjg2Mzc1NkMuNzgxNDk0LS4zNDk2MTYgLjcwOTUxNC0uMjc3NjM2IC4wNTE0MTQtLjE1NDI0MlYwSDIuNTE5Mjg5Vi0uMTU0MjQyQzEuODIwMDU4LS4xODUwOTEgMS42NDUyNS0uMzM5MzMzIDEuNjQ1MjUtLjkyNTQ1M1YtMy4yMzkwODZDMS42NDUyNS0zLjU2ODEzNSAyLjA4NzQxMS00LjA4MjI3NiAyLjM2NTA0Ny00LjA4MjI3NkMyLjQyNjc0My00LjA4MjI3NiAyLjUxOTI4OS00LjAzMDg2MiAyLjYzMjQtMy45MjgwMzRDMi43OTY5MjUtMy43ODQwNzUgMi45MTAwMzYtMy43MjIzNzggMy4wNDM3MTItMy43MjIzNzhDMy4yOTA1LTMuNzIyMzc4IDMuNDQ0NzQyLTMuODk3MTg1IDMuNDQ0NzQyLTQuMTg1MTA0QzMuNDQ0NzQyLTQuNTI0NDM3IDMuMjI4ODAzLTQuNzMwMDkzIDIuODc5MTg3LTQuNzMwMDkzQzIuNDQ3MzA5LTQuNzMwMDkzIDIuMTQ5MTA4LTQuNDkzNTg5IDEuNjQ1MjUtMy43NjM1MDlWLTQuNzA5NTI4TDEuNTkzODM2LTQuNzMwMDkzQzEuMDQ4ODQ3LTQuNTAzODcxIC42Nzg2NjYtNC4zNzAxOTUgLjA3MTk4LTQuMTc0ODIxVi00LjAxMDI5NlonLz4KPHVzZSBpZD0nZzE0LTcxJyB4bGluazpocmVmPScjZzEwLTcxJyB0cmFuc2Zvcm09J3NjYWxlKDEuMzUxMzQxKScvPgo8cGF0aCBpZD0nZzE4LTYxJyBkPSdNNy4wNjQyOTEtMy4zNjI0NzlDNy4yMTg1MzMtMy4zNjI0NzkgNy40MTM5MDctMy4zNjI0NzkgNy40MTM5MDctMy41NjgxMzVTNy4yMTg1MzMtMy43NzM3OTIgNy4wNzQ1NzQtMy43NzM3OTJILjkxNTE3Qy43NzEyMTEtMy43NzM3OTIgLjU3NTgzNy0zLjc3Mzc5MiAuNTc1ODM3LTMuNTY4MTM1Uy43NzEyMTEtMy4zNjI0NzkgLjkyNTQ1My0zLjM2MjQ3OUg3LjA2NDI5MVpNNy4wNzQ1NzQtMS4zNjc2MTRDNy4yMTg1MzMtMS4zNjc2MTQgNy40MTM5MDctMS4zNjc2MTQgNy40MTM5MDctMS41NzMyN1M3LjIxODUzMy0xLjc3ODkyNiA3LjA2NDI5MS0xLjc3ODkyNkguOTI1NDUzQy43NzEyMTEtMS43Nzg5MjYgLjU3NTgzNy0xLjc3ODkyNiAuNTc1ODM3LTEuNTczMjdTLjc3MTIxMS0xLjM2NzYxNCAuOTE1MTctMS4zNjc2MTRINy4wNzQ1NzRaJy8+CjxwYXRoIGlkPSdnOS01OCcgZD0nTTEuOTc0My0uNTQ0OTg5QzEuOTc0My0uODQzMTkxIDEuNzI3NTEyLTEuMDg5OTc4IDEuNDI5MzExLTEuMDg5OTc4Uy44ODQzMjItLjg0MzE5MSAuODg0MzIyLS41NDQ5ODlTMS4xMzExMDkgMCAxLjQyOTMxMSAwUzEuOTc0My0uMjQ2Nzg3IDEuOTc0My0uNTQ0OTg5WicvPgo8cGF0aCBpZD0nZzktNTknIGQ9J00yLjA4NzQxMS0uMDEwMjgzQzIuMDg3NDExLS42ODg5NDggMS44MzAzNC0xLjA4OTk3OCAxLjQyOTMxMS0xLjA4OTk3OEMxLjA4OTk3OC0xLjA4OTk3OCAuODg0MzIyLS44MzI5MDggLjg4NDMyMi0uNTQ0OTg5Qy44ODQzMjItLjI2NzM1MyAxLjA4OTk3OCAwIDEuNDI5MzExIDBDMS41NTI3MDQgMCAxLjY4NjM4MS0uMDQxMTMxIDEuNzg5MjA5LS4xMzM2NzdDMS44MjAwNTgtLjE1NDI0MiAxLjgzMDM0LS4xNjQ1MjUgMS44NDA2MjMtLjE2NDUyNVMxLjg2MTE4OS0uMTU0MjQyIDEuODYxMTg5LS4wMTAyODNDMS44NjExODkgLjc1MDY0NSAxLjUwMTI5IDEuMzY3NjE0IDEuMTYxOTU4IDEuNzA2OTQ3QzEuMDQ4ODQ3IDEuODIwMDU4IDEuMDQ4ODQ3IDEuODQwNjIzIDEuMDQ4ODQ3IDEuODcxNDcyQzEuMDQ4ODQ3IDEuOTQzNDUxIDEuMTAwMjYxIDEuOTg0NTgzIDEuMTUxNjc1IDEuOTg0NTgzQzEuMjY0Nzg2IDEuOTg0NTgzIDIuMDg3NDExIDEuMTkyODA2IDIuMDg3NDExLS4wMTAyODNaJy8+CjxwYXRoIGlkPSdnMTAtNzEnIGQ9J003LjI4MDIzLTYuODA3MjIxTDcuMTI1OTg4LTYuODQ4MzUyQzYuOTUxMTgtNi42MDE1NjUgNi43NzYzNzMtNi40OTg3MzcgNi41MDkwMi02LjQ5ODczN0M2LjQwNjE5MS02LjQ5ODczNyA2LjI4Mjc5OC02LjUyOTU4NSA2LjA1NjU3Ni02LjYwMTU2NUM1LjU0MjQzNS02Ljc2NjA5IDUuMTAwMjc0LTYuODQ4MzUyIDQuNjc4Njc5LTYuODQ4MzUyQzIuNTA5MDA2LTYuODQ4MzUyIC41MzQ3MDYtNC43OTE3OSAuNTM0NzA2LTIuNTI5NTcyQy41MzQ3MDYtMS44MzAzNCAuODMyOTA4LTEuMTEwNTQ0IDEuMzE2Mi0uNjE2OTY5QzEuODQwNjIzLS4wOTI1NDUgMi41OTEyNjggLjE4NTA5MSAzLjQ4NTg3MyAuMTg1MDkxQzQuMzkwNzYgLjE4NTA5MSA1LjEzMTEyMy0uMDEwMjgzIDUuOTIyODk5LS40NTI0NDRMNi40MjY3NTctMi4zNzUzMjlDNi41OTEyODItMi45NTExNjcgNi43NTU4MDctMy4wNzQ1NjEgNy40MjQxOS0zLjExNTY5MlYtMy4yODAyMTdINC42ODg5NjJWLTMuMTE1NjkyQzQuODEyMzU2LTMuMTA1NDA5IDQuOTQ2MDMyLTMuMDg0ODQzIDQuOTg3MTYzLTMuMDg0ODQzQzUuMzI2NDk2LTMuMDUzOTk1IDUuNDkxMDIxLTIuOTUxMTY3IDUuNDkxMDIxLTIuNzY2MDc2QzUuNDkxMDIxLTIuNTM5ODU0IDUuNDI5MzI0LTIuMjUxOTM2IDUuMjAzMTAyLTEuNDkxMDA4QzQuOTc2ODgxLS43NTA2NDUgNC45NDYwMzItLjY2ODM4MyA0LjgyMjYzOC0uNTQ0OTg5QzQuNTk2NDE3LS4zMTg3NjcgNC4yMDU2Ny0uMTk1MzczIDMuNzQyOTQzLS4xOTUzNzNDMi40MTY0NjEtLjE5NTM3MyAxLjY2NTgxNS0uOTU2MzAxIDEuNjY1ODE1LTIuMzAzMzVDMS42NjU4MTUtMy41NjgxMzUgMi4xNjk2NzMtNC44NzQwNTMgMi45ODIwMTUtNS43Mzc4MDlDMy40NDQ3NDItNi4yMjExMDEgNC4wODIyNzYtNi40OTg3MzcgNC43NjA5NDItNi40OTg3MzdDNS40MjkzMjQtNi40OTg3MzcgNS45OTQ4NzktNi4yMjExMDEgNi4zMDMzNjMtNS43NDgwOTFDNi40Njc4ODgtNS40ODA3MzggNi41Mzk4NjgtNS4yNjQ3OTkgNi41OTEyODItNC44MTIzNTZMNi43NzYzNzMtNC43ODE1MDdMNy4yODAyMy02LjgwNzIyMVonLz4KPHBhdGggaWQ9J2cxMC0xMjAnIGQ9J000LjEzMzY5LTEuMTQxMzkyQzQuMDUxNDI4LTEuMDQ4ODQ3IDQuMDAwMDE0LS45ODcxNSAzLjkwNzQ2OC0uODYzNzU2QzMuNjcwOTY0LS41NTUyNzIgMy41NDc1Ny0uNDUyNDQ0IDMuNDM0NDU5LS40NTI0NDRDMy4yODAyMTctLjQ1MjQ0NCAzLjE4NzY3MS0uNTg2MTIgMy4xMTU2OTItLjg3NDAzOUMzLjA5NTEyNi0uOTU2MzAxIDMuMDg0ODQzLTEuMDE3OTk4IDMuMDc0NTYxLTEuMDQ4ODQ3QzIuODE3NDktMi4wODc0MTEgMi43MDQzNzktMi41NjA0MiAyLjcwNDM3OS0yLjcxNDY2MkMzLjE1NjgyMy0zLjUwNjQzOSAzLjUyNzAwNC0zLjk1ODg4MiAzLjcxMjA5NS0zLjk1ODg4MkMzLjc3Mzc5Mi0zLjk1ODg4MiAzLjg1NjA1NC0zLjkyODAzNCAzLjk1ODg4Mi0zLjg3NjYyQzQuMDgyMjc2LTMuODA0NjQgNC4xNTQyNTYtMy43ODQwNzUgNC4yMzY1MTgtMy43ODQwNzVDNC40NTI0NTctMy43ODQwNzUgNC41OTY0MTctMy45MzgzMTcgNC41OTY0MTctNC4xNTQyNTZTNC40MjE2MDktNC41MzQ3MiA0LjE3NDgyMS00LjUzNDcyQzMuNzIyMzc4LTQuNTM0NzIgMy4zMzE2MzEtNC4xNjQ1MzkgMi42MjIxMTctMy4wNjQyNzhMMi41MDkwMDYtMy42Mjk4MzJDMi4zNjUwNDctNC4zMjkwNjQgMi4yNTE5MzYtNC41MzQ3MiAxLjk3NDMtNC41MzQ3MkMxLjc0ODA3OC00LjUzNDcyIDEuMzk4NDYyLTQuNDQyMTc0IC43NzEyMTEtNC4yMzY1MThMLjY1ODEtNC4xOTUzODdMLjY5OTIzMS00LjA0MTE0NUMxLjA4OTk3OC00LjEzMzY5IDEuMTgyNTIzLTQuMTU0MjU2IDEuMjc1MDY5LTQuMTU0MjU2QzEuNTMyMTM5LTQuMTU0MjU2IDEuNTkzODM2LTQuMDYxNzEgMS43Mzc3OTUtMy40NDQ3NDJMMi4wMzU5OTctMi4xNzk5NTZMMS4xOTI4MDYtLjk3Njg2N0MuOTg3MTUtLjY2ODM4MyAuNzgxNDk0LS40ODMyOTIgLjY2ODM4My0uNDgzMjkyQy42MDY2ODYtLjQ4MzI5MiAuNTAzODU4LS41MTQxNDEgLjQwMTAzLS41NzU4MzdDLjI2NzM1My0uNjQ3ODE3IC4xNTQyNDItLjY3ODY2NiAuMDcxOTgtLjY3ODY2NkMtLjEyMzM5NC0uNjc4NjY2LS4yNzc2MzYtLjUyNDQyMy0uMjc3NjM2LS4zMTg3NjdDLS4yNzc2MzYtLjA1MTQxNC0uMDcxOTggLjExMzExMSAuMjM2NTA1IC4xMTMxMTFDLjU1NTI3MiAuMTEzMTExIC42Nzg2NjYgLjAyMDU2NiAxLjE5MjgwNi0uNjA2Njg2QzEuNDcwNDQyLS45MzU3MzYgMS42ODYzODEtMS4yMTMzNzIgMi4xMTgyNTktMS44MDk3NzVMMi40MjY3NDMtLjU3NTgzN0MyLjU2MDQyLS4wNTE0MTQgMi42OTQwOTcgLjExMzExMSAzLjAyMzE0NiAuMTEzMTExQzMuNDEzODkzIC4xMTMxMTEgMy42ODEyNDYtLjEzMzY3NyA0LjI3NzY0OS0xLjA1OTEzTDQuMTMzNjktMS4xNDEzOTJaJy8+CjxwYXRoIGlkPSdnMTAtMTIxJyBkPSdNLjE1NDI0Mi00LjExMzEyNEMuMjg3OTE5LTQuMTQzOTczIC4zNTk4OTgtNC4xNTQyNTYgLjQ3MzAwOS00LjE1NDI1NkMxLjA1OTEzLTQuMTU0MjU2IDEuMjEzMzcyLTMuODk3MTg1IDEuNjg2MzgxLTIuMTI4NTQyQzEuODYxMTg5LTEuNDYwMTU5IDIuMTA3OTc2LS4yNTcwNyAyLjEwNzk3Ni0uMDgyMjYyQzIuMTA3OTc2IC4wODIyNjIgMi4wNDYyNzkgLjI0Njc4NyAxLjg5MjAzNyAuNDMxODc4QzEuNTczMjcgLjg1MzQ3MyAxLjM2NzYxNCAxLjEyMDgyNiAxLjI1NDUwMyAxLjI0NDIyQzEuMDM4NTY0IDEuNDcwNDQyIC45MTUxNyAxLjU1MjcwNCAuNzgxNDk0IDEuNTUyNzA0Qy43MTk3OTcgMS41NTI3MDQgLjY0NzgxNyAxLjUyMTg1NiAuNTM0NzA2IDEuNDM5NTk0Qy4zODA0NjQgMS4zMTYyIC4yNjczNTMgMS4yNjQ3ODYgLjE1NDI0MiAxLjI2NDc4NkMtLjA3MTk4IDEuMjY0Nzg2LS4yNDY3ODcgMS40Mzk1OTQtLjI0Njc4NyAxLjY2NTgxNUMtLjI0Njc4NyAxLjkyMjg4Ni0uMDIwNTY2IDIuMTE4MjU5IC4yNzc2MzYgMi4xMTgyNTlDLjkzNTczNiAyLjExODI1OSAyLjI4Mjc4NCAuNTc1ODM3IDMuMzkzMzI4LTEuNDYwMTU5QzQuMDkyNTU5LTIuNzI0OTQ1IDQuMzgwNDc4LTMuNDY1MzA3IDQuMzgwNDc4LTMuOTY5MTY1QzQuMzgwNDc4LTQuMjc3NjQ5IDQuMTIzNDA3LTQuNTM0NzIgMy44MTQ5MjMtNC41MzQ3MkMzLjU3ODQxOC00LjUzNDcyIDMuNDEzODkzLTQuMzgwNDc4IDMuNDEzODkzLTQuMTU0MjU2QzMuNDEzODkzLTQuMDAwMDE0IDMuNDk2MTU2LTMuODg2OTAzIDMuNzAxODEyLTMuNzUzMjI2QzMuODk3MTg1LTMuNjQwMTE1IDMuOTY5MTY1LTMuNTQ3NTcgMy45NjkxNjUtMy40MDM2MTFDMy45NjkxNjUtMi45OTIyOTggMy41ODg3MDEtMi4xOTAyMzkgMi43MTQ2NjItLjc0MDM2MkwyLjUwOTAwNi0xLjkzMzE2OUMyLjM1NDc2NC0yLjgzODA1NiAxLjc3ODkyNi00LjUzNDcyIDEuNjI0Njg0LTQuNTM0NzJIMS41ODM1NTNDMS41NzMyNy00LjUyNDQzNyAxLjUzMjEzOS00LjUyNDQzNyAxLjQ5MTAwOC00LjUyNDQzN0MxLjM5ODQ2Mi00LjUxNDE1NCAxLjAyODI4MS00LjQ1MjQ1NyAuNDgzMjkyLTQuMzQ5NjI5Qy40MzE4NzgtNC4zMzkzNDYgLjI5ODIwMi00LjMwODQ5OCAuMTU0MjQyLTQuMjg3OTMyVi00LjExMzEyNFonLz4KPHBhdGggaWQ9J2cxMC0xMjInIGQ9J00uODMyOTA4LTMuMTc3Mzg5QzEuMDQ4ODQ3LTMuNjkxNTI5IDEuMTgyNTIzLTMuNzg0MDc1IDEuNjY1ODE1LTMuNzg0MDc1SDMuMTY3MTA2TC0uMDIwNTY2IC4wNDExMzFMLjA3MTk4IC4xMzM2NzdDLjIzNjUwNSAwIC4zNzAxODEtLjA1MTQxNCAuNTQ0OTg5LS4wNTE0MTRDLjc5MTc3Ni0uMDUxNDE0IDEuMTMxMTA5IC4wODIyNjIgMS42MTQ0MDEgLjM4MDQ2NEMyLjEyODU0MiAuNjk5MjMxIDIuNDc4MTU4IC44MzI5MDggMi43NjYwNzYgLjgzMjkwOEMzLjI4MDIxNyAuODMyOTA4IDMuNzMyNjYgLjQ2MjcyNyAzLjczMjY2IC4wNTE0MTRDMy43MzI2Ni0uMTY0NTI1IDMuNTg4NzAxLS4zMTg3NjcgMy4zNzI3NjItLjMxODc2N0MzLjE2NzEwNi0uMzE4NzY3IDMuMDIzMTQ2LS4xODUwOTEgMy4wMjMxNDYgMEMzLjAyMzE0NiAuMDkyNTQ1IDMuMDUzOTk1IC4xOTUzNzMgMy4xMTU2OTIgLjMwODQ4NEMzLjE0NjU0IC4zNzAxODEgMy4xNjcxMDYgLjQzMTg3OCAzLjE2NzEwNiAuNDYyNzI3QzMuMTY3MTA2IC41NTUyNzIgMy4wNTM5OTUgLjYxNjk2OSAyLjg4OTQ3IC42MTY5NjlDMi42MzI0IC42MTY5NjkgMi41MDkwMDYgLjUzNDcwNiAyLjE2OTY3MyAuMTAyODI4QzEuNzE3MjI5LS40ODMyOTIgMS41MjE4NTYtLjYxNjk2OSAuOTI1NDUzLS43NTA2NDVMMy45MDc0NjgtNC4yODc5MzJWLTQuNDAxMDQzSC45ODcxNUwuNjY4MzgzLTMuMjE4NTJMLjgzMjkwOC0zLjE3NzM4OVonLz4KPHBhdGggaWQ9J2cxLTcxJyBkPSdNMTAuNDkxMTY5LTMuOTg4MDM0SDUuNzI0OTgyVi0zLjY0MDY0NEM2LjkyMDAwMy0zLjU3MTE2NiA3LjEyODQzNi0zLjQxODMxNSA3LjEyODQzNi0yLjY2Nzk1M1YtMS4yMDg5MTZDNy4xMjg0MzYtLjUwMDI0MSA2LjcyNTQ2NC0uMTk0NTM4IDUuNzk0NDYtLjE5NDUzOEM0LjkxOTAzOC0uMTk0NTM4IDQuMzM1NDIzLS40NTg1NTQgMy44NzY4NjktMS4wNTYwNjVDMy4yNjU0NjMtMS44MzQyMTggMi45NzM2NTYtMy4wMjkyMzggMi45NzM2NTYtNC42OTY3MDlDMi45NzM2NTYtNy42MDA4ODYgMy44NDkwNzgtOS4xNDMyOTcgNS41MzA0NDQtOS4xNDMyOTdDNi4xNjk2NDEtOS4xNDMyOTcgNi43NjcxNTEtOC44OTMxNzYgNy4zNzg1NTctOC4zNjUxNDRDNy45NzYwNjctNy44MzcxMTEgOC4yOTU2NjYtNy4zNjQ2NjEgOC43ODIwMTEtNi4zMDg1OTdIOS4xMjk0MDFWLTkuNTYwMTY0SDguNzU0MjJDOC41NTk2ODItOS4wNzM4MTkgOC40MDY4MzEtOC45MjA5NjcgOC4xNDI4MTQtOC45MjA5NjdDOC4wMTc3NTQtOC45MjA5NjcgNy44MDkzMi04Ljk3NjU1IDcuNTAzNjE3LTkuMTE1NTA2QzYuNjgzNzc4LTkuNDQ5IDYuMDE2Nzg5LTkuNjAxODUxIDUuMzQ5ODAxLTkuNjAxODUxQzIuNTg0NTc5LTkuNjAxODUxIC41MTQxMzctNy40NjE5MzEgLjUxNDEzNy00LjU5OTQ0UzIuNTQyODkzIC4yNjQwMTYgNS40NjA5NjYgLjI2NDAxNkM2Ljg5MjIxMSAuMjY0MDE2IDguNDA2ODMxLS4wNjk0NzggOS4yOTYxNDgtLjU5NzUxVi0yLjM2MjI1QzkuMjk2MTQ4LTMuMzYyNzMyIDkuNDQ5LTMuNTI5NDc5IDEwLjQ5MTE2OS0zLjY0MDY0NFYtMy45ODgwMzRaJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PSc4Ni43NzA2MTgnIHk9JzEwNy41OTY1MTMnIHhsaW5rOmhyZWY9JyNnMS03MScvPgo8dXNlIHg9JzEwMC43MjEyNTInIHk9JzEwNy41OTY1MTMnIHhsaW5rOmhyZWY9JyNnMjItNjEnLz4KPHVzZSB4PScxMTQuNjU3OTMzJyB5PSc3OS41NjE2NzUnIHhsaW5rOmhyZWY9JyNnMy01MCcvPgo8dXNlIHg9JzExNC42NTc5MzMnIHk9JzEwNC42NTM0MDInIHhsaW5rOmhyZWY9JyNnMy01MicvPgo8dXNlIHg9JzEyOC45MjgyODcnIHk9JzkwLjU2MDM0NycgeGxpbms6aHJlZj0nI2cxNC03MScvPgo8dXNlIHg9JzEzOC45OTg0ODUnIHk9JzkyLjY1MjQ5MicgeGxpbms6aHJlZj0nI2cxMC0xMjAnLz4KPHVzZSB4PScxNDMuNjExOTYyJyB5PSc5Mi42NTI0OTInIHhsaW5rOmhyZWY9JyNnMTAtMTIwJy8+Cjx1c2UgeD0nMTU4LjY4NjE4NicgeT0nOTAuNTYwMzQ3JyB4bGluazpocmVmPScjZzE0LTcxJy8+Cjx1c2UgeD0nMTY4Ljc1NjM4NScgeT0nOTIuNjUyNDkyJyB4bGluazpocmVmPScjZzEwLTEyMCcvPgo8dXNlIHg9JzE3My4zNjk4NjInIHk9JzkyLjY1MjQ5MicgeGxpbms6aHJlZj0nI2cxMC0xMjEnLz4KPHVzZSB4PScxODguNDEzMjQxJyB5PSc5MC41NjAzNDcnIHhsaW5rOmhyZWY9JyNnMTQtNzEnLz4KPHVzZSB4PScxOTguNDgzNDQnIHk9JzkyLjY1MjQ5MicgeGxpbms6aHJlZj0nI2cxMC0xMjAnLz4KPHVzZSB4PScyMDMuMDk2OTE3JyB5PSc5Mi42NTI0OTInIHhsaW5rOmhyZWY9JyNnMTAtMTIyJy8+Cjx1c2UgeD0nMTI4Ljk0MzcxNycgeT0nMTA3LjQ5NjgzNScgeGxpbms6aHJlZj0nI2cxNC03MScvPgo8dXNlIHg9JzEzOS4wMTM5MTUnIHk9JzEwOS41ODg5OCcgeGxpbms6aHJlZj0nI2cxMC0xMjEnLz4KPHVzZSB4PScxNDMuNTk2NTQ4JyB5PScxMDkuNTg4OTgnIHhsaW5rOmhyZWY9JyNnMTAtMTIwJy8+Cjx1c2UgeD0nMTU4LjcwMTYxNicgeT0nMTA3LjQ5NjgzNScgeGxpbms6aHJlZj0nI2cxNC03MScvPgo8dXNlIHg9JzE2OC43NzE4MTUnIHk9JzEwOS41ODg5OCcgeGxpbms6aHJlZj0nI2cxMC0xMjEnLz4KPHVzZSB4PScxNzMuMzU0NDQ3JyB5PScxMDkuNTg4OTgnIHhsaW5rOmhyZWY9JyNnMTAtMTIxJy8+Cjx1c2UgeD0nMTg4LjQyODY3MScgeT0nMTA3LjQ5NjgzNScgeGxpbms6aHJlZj0nI2cxNC03MScvPgo8dXNlIHg9JzE5OC40OTg4NycgeT0nMTA5LjU4ODk4JyB4bGluazpocmVmPScjZzEwLTEyMScvPgo8dXNlIHg9JzIwMy4wODE1MDInIHk9JzEwOS41ODg5OCcgeGxpbms6aHJlZj0nI2cxMC0xMjInLz4KPHVzZSB4PScxMjkuMjI3NTY0JyB5PScxMjQuNDMzMzIzJyB4bGluazpocmVmPScjZzE0LTcxJy8+Cjx1c2UgeD0nMTM5LjI5Nzc2MycgeT0nMTI2LjUyNTQ2OCcgeGxpbms6aHJlZj0nI2cxMC0xMjInLz4KPHVzZSB4PScxNDMuMzEyNjc3JyB5PScxMjYuNTI1NDY4JyB4bGluazpocmVmPScjZzEwLTEyMCcvPgo8dXNlIHg9JzE1OC45ODU0NjQnIHk9JzEyNC40MzMzMjMnIHhsaW5rOmhyZWY9JyNnMTQtNzEnLz4KPHVzZSB4PScxNjkuMDU1NjYyJyB5PScxMjYuNTI1NDY4JyB4bGluazpocmVmPScjZzEwLTEyMicvPgo8dXNlIHg9JzE3My4wNzA1NzcnIHk9JzEyNi41MjU0NjgnIHhsaW5rOmhyZWY9JyNnMTAtMTIxJy8+Cjx1c2UgeD0nMTg4LjcxMjUxOScgeT0nMTI0LjQzMzMyMycgeGxpbms6aHJlZj0nI2cxNC03MScvPgo8dXNlIHg9JzE5OC43ODI3MTcnIHk9JzEyNi41MjU0NjgnIHhsaW5rOmhyZWY9JyNnMTAtMTIyJy8+Cjx1c2UgeD0nMjAyLjc5NzYzMicgeT0nMTI2LjUyNTQ2OCcgeGxpbms6aHJlZj0nI2cxMC0xMjInLz4KPHVzZSB4PScyMTIuNTkxMjY2JyB5PSc3OS41NjE2NzUnIHhsaW5rOmhyZWY9JyNnMy01MScvPgo8dXNlIHg9JzIxMi41OTEyNjYnIHk9JzEwNC42NTM0MDInIHhsaW5rOmhyZWY9JyNnMy01MycvPgo8dXNlIHg9JzIyMy40MzAwMycgeT0nMTA3LjU5NjUxMycgeGxpbms6aHJlZj0nI2cxMy01OScvPgo8dXNlIHg9JzIzOS4zMDM5MDQnIHk9JzEwNy41OTY1MTMnIHhsaW5rOmhyZWY9JyNnMjEtMTExJy8+Cjx1c2UgeD0nMjQ2LjI3Nzc1MicgeT0nMTA3LjU5NjUxMycgeGxpbms6aHJlZj0nI2cyMS0xMTQnLz4KPHVzZSB4PScyNjIuOTMyNzgnIHk9Jzc5LjU2MTY3NScgeGxpbms6aHJlZj0nI2czLTUwJy8+Cjx1c2UgeD0nMjYyLjkzMjc4JyB5PScxMDQuNjUzNDAyJyB4bGluazpocmVmPScjZzMtNTInLz4KPHVzZSB4PScyNzcuMjAzMTM0JyB5PSc5MC41NjAzNDcnIHhsaW5rOmhyZWY9JyNnMTQtNzEnLz4KPHVzZSB4PScyODcuMjczMzMyJyB5PSc5Mi42NjczNTknIHhsaW5rOmhyZWY9JyNnMTctNDknLz4KPHVzZSB4PScyOTIuNDM0MDE4JyB5PSc5Mi42NjczNTknIHhsaW5rOmhyZWY9JyNnMTctNDknLz4KPHVzZSB4PSczMDguMDU1NDcnIHk9JzkwLjU2MDM0NycgeGxpbms6aHJlZj0nI2cxNC03MScvPgo8dXNlIHg9JzMxOC4xMjU2NjgnIHk9JzkyLjY2NzM1OScgeGxpbms6aHJlZj0nI2cxNy00OScvPgo8dXNlIHg9JzMyMy4yODYzNTQnIHk9JzkyLjY2NzM1OScgeGxpbms6aHJlZj0nI2cxNy01MCcvPgo8dXNlIHg9JzMzOC45MDc4MDcnIHk9JzkwLjU2MDM0NycgeGxpbms6aHJlZj0nI2cxNC03MScvPgo8dXNlIHg9JzM0OC45NzgwMDUnIHk9JzkyLjY2NzM1OScgeGxpbms6aHJlZj0nI2cxNy00OScvPgo8dXNlIHg9JzM1NC4xMzg2OTEnIHk9JzkyLjY2NzM1OScgeGxpbms6aHJlZj0nI2cxNy01MScvPgo8dXNlIHg9JzI3Ny4yMDMxMzQnIHk9JzEwNy40OTY4MzUnIHhsaW5rOmhyZWY9JyNnMTQtNzEnLz4KPHVzZSB4PScyODcuMjczMzMyJyB5PScxMDkuNjAzODQ4JyB4bGluazpocmVmPScjZzE3LTUwJy8+Cjx1c2UgeD0nMjkyLjQzNDAxOCcgeT0nMTA5LjYwMzg0OCcgeGxpbms6aHJlZj0nI2cxNy00OScvPgo8dXNlIHg9JzMwOC4wNTU0NycgeT0nMTA3LjQ5NjgzNScgeGxpbms6aHJlZj0nI2cxNC03MScvPgo8dXNlIHg9JzMxOC4xMjU2NjgnIHk9JzEwOS42MDM4NDgnIHhsaW5rOmhyZWY9JyNnMTctNTAnLz4KPHVzZSB4PSczMjMuMjg2MzU0JyB5PScxMDkuNjAzODQ4JyB4bGluazpocmVmPScjZzE3LTUwJy8+Cjx1c2UgeD0nMzM4LjkwNzgwNycgeT0nMTA3LjQ5NjgzNScgeGxpbms6aHJlZj0nI2cxNC03MScvPgo8dXNlIHg9JzM0OC45NzgwMDUnIHk9JzEwOS42MDM4NDgnIHhsaW5rOmhyZWY9JyNnMTctNTAnLz4KPHVzZSB4PSczNTQuMTM4NjkxJyB5PScxMDkuNjAzODQ4JyB4bGluazpocmVmPScjZzE3LTUxJy8+Cjx1c2UgeD0nMjc3LjIwMzEzNCcgeT0nMTI0LjQzMzMyMycgeGxpbms6aHJlZj0nI2cxNC03MScvPgo8dXNlIHg9JzI4Ny4yNzMzMzInIHk9JzEyNi41NDAzMzYnIHhsaW5rOmhyZWY9JyNnMTctNTEnLz4KPHVzZSB4PScyOTIuNDM0MDE4JyB5PScxMjYuNTQwMzM2JyB4bGluazpocmVmPScjZzE3LTQ5Jy8+Cjx1c2UgeD0nMzA4LjA1NTQ3JyB5PScxMjQuNDMzMzIzJyB4bGluazpocmVmPScjZzE0LTcxJy8+Cjx1c2UgeD0nMzE4LjEyNTY2OCcgeT0nMTI2LjU0MDMzNicgeGxpbms6aHJlZj0nI2cxNy01MScvPgo8dXNlIHg9JzMyMy4yODYzNTQnIHk9JzEyNi41NDAzMzYnIHhsaW5rOmhyZWY9JyNnMTctNTAnLz4KPHVzZSB4PSczMzguOTA3ODA3JyB5PScxMjQuNDMzMzIzJyB4bGluazpocmVmPScjZzE0LTcxJy8+Cjx1c2UgeD0nMzQ4Ljk3ODAwNScgeT0nMTI2LjU0MDMzNicgeGxpbms6aHJlZj0nI2cxNy01MScvPgo8dXNlIHg9JzM1NC4xMzg2OTEnIHk9JzEyNi41NDAzMzYnIHhsaW5rOmhyZWY9JyNnMTctNTEnLz4KPHVzZSB4PSczNjQuNzc4ODIzJyB5PSc3OS41NjE2NzUnIHhsaW5rOmhyZWY9JyNnMy01MScvPgo8dXNlIHg9JzM2NC43Nzg4MjMnIHk9JzEwNC42NTM0MDInIHhsaW5rOmhyZWY9JyNnMy01MycvPgo8dXNlIHg9JzM3NS42MTc1ODgnIHk9JzEwNy41OTY1MTMnIHhsaW5rOmhyZWY9JyNnMTMtNTgnLz4KPC9nPgo8L3N2Zz4=)
The components of the matrix are related to the gradients above:
 ,
,  ,
etc. Formally, G is the outer (or dyadic) product of g. Here,
the main thing that results from this relation is that G is
symmetric (
,
etc. Formally, G is the outer (or dyadic) product of g. Here,
the main thing that results from this relation is that G is
symmetric ( ), which means that there are
only six independent components in the matrix. Thus,
six numbers are recorded in this format. Generally, these are stored
as columns, so that the files would be (following the previous
section’s notation) an
), which means that there are
only six independent components in the matrix. Thus,
six numbers are recorded in this format. Generally, these are stored
as columns, so that the files would be (following the previous
section’s notation) an  array of numbers.
array of numbers.
However, there is the little wrinkle that different programs write out the components in different ways!
The standard style for inputting into AFNI functions is ‘diagonal first’ g-matrix:

while, for example, another output style is ‘row first’ g-matrix (and it may often explicitly include the factors of two from the symmetry of the off-diagonals):

Each of these formats record equivalent information, so it’s just a matter of using the appropriate one with the appropriate software. When using these dyadic g-matrices to record spatial information, the b-value information sits by itself again, similar as with the g vector gradients.
As a final case, one may include the magnitude of the magnetic fields with the spatial directionality in a single expression, the b-matrix:

where every component of the above dyadic matrix, G, is simply multiplied by the DW factor, b. All the other notations, symmetries and relations for the b-matrices remain the same as for the g-matrices, including the distinctions in row- or diagonal-first notations.
Of note, TORTOISE functions typically use and output a row-first b-matrix (with the factors of 2, as above).
Note
In some versions of TORTOISE v2.*, there is an ‘AFNI_SAVE’ option that can be used when exporting the b-matrix; in this case, the output matrix is diagonal-first, such as would be called “AFNI-style” above. However, this issue is further complicated by the fact that some versions of TORTOISE had the factor of 2 included, which AFNI typically does not use… This is actually easily managed because the conversion from matrix-to-vector is not affected by that factor of two (in an interesting algebraic quirk, only the sign information comes from the off-diagonal elements for this operation); so one could convert the TORTOISE matrix to a vector and then to an AFNI style matrix in such cases.
TORTOISE v3.* does not appear to have these options as yet; we only deal with and convert the TORTOISE-style matrices.
The following figure shows a comparison of the same few lines of b- and g- matrix and vector formats:
Grad/matrix selection |
Style description |
|---|---|
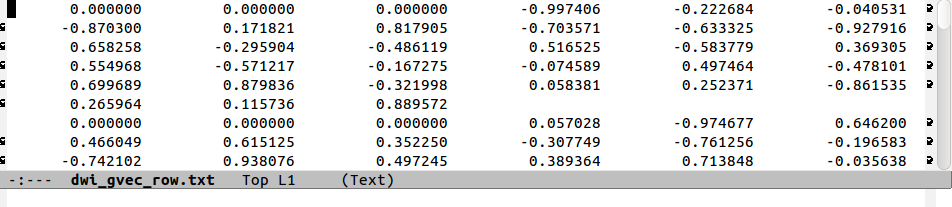
|
(row, unit-magnitude) gradient file; note the arrows on the edge signifying that each line is actually wrapped over many rows of the text editor |
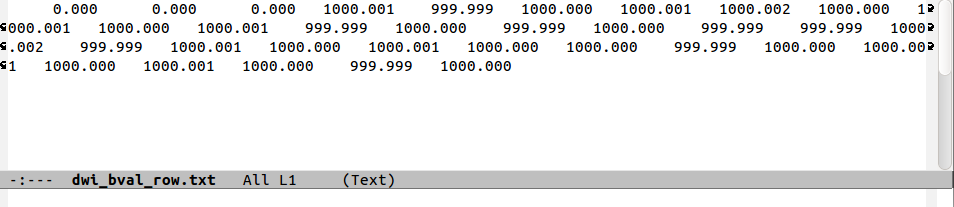
|
(row) b-value file; the single line is wrapped around to many rows in the text editor |

|
(column) b-value file |
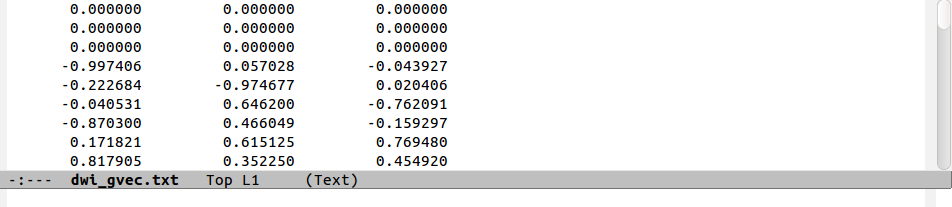
|
(column, unit-magnitude) gradient file |
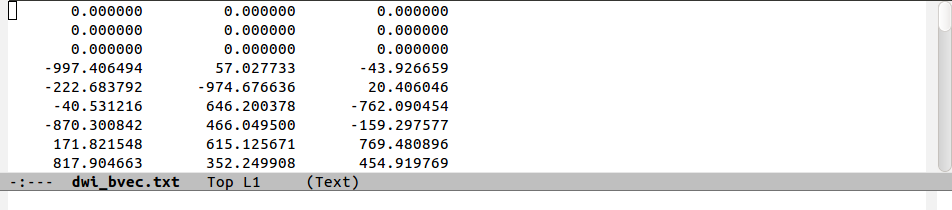
|
(column, DW-scaled) gradient file |
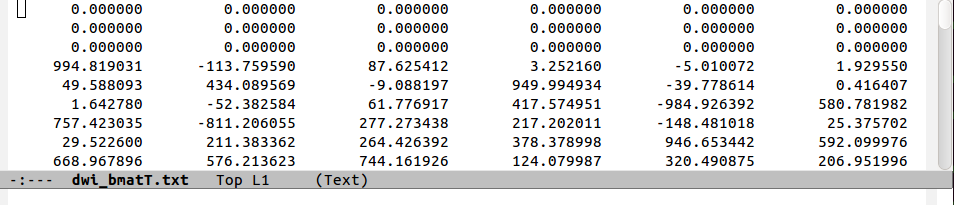
|
row-first (TORTOISE-style) b-matrix; the three columns with no negative values contain the diagonal elements of the matrix; this has a different order and a factor of 2 scaling the off-diagonal elements, compared to the ‘AFNI-style’. |
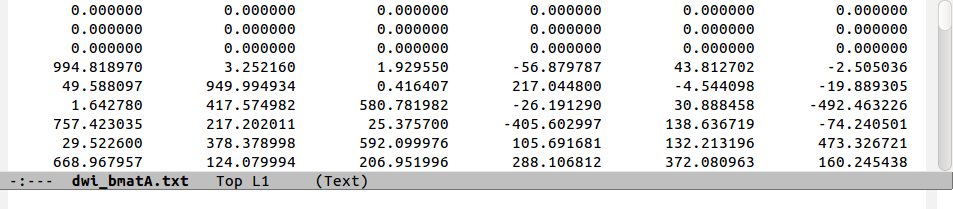
|
diagonal-first (AFNI-style) b-matrix; the three columns with no negative values contain the diagonal elements of the matrix. |
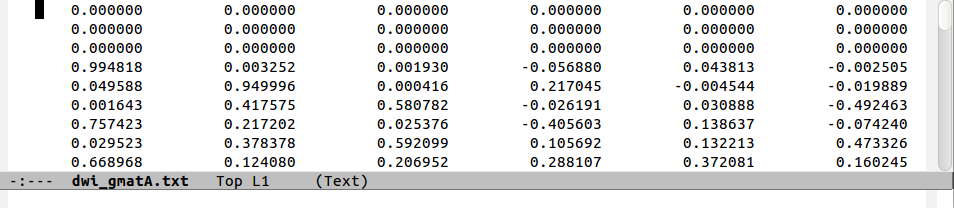
|
row-first (AFNI-style) g-matrix |
Note that in the ‘diagonal-first’ matrix case, the first three columns
contain only non-negative ( ) numbers. This will always be the
case, since the b- or g-matrix is positive definite, and this
property provides a solid hint as to the style of a given matrix
output. (Columns of off-diagonal elements may or may not contain
negatives). In the ‘row-first’ cases columns 0, 2 and 5 contain the
matrix diagonals. The factors of two in the columns representing
off-diagonal matrix elements is apparent when comparing the
b-matrices. Finally, one can see how the b=1000 information
translates into the b-matrix file by comparing the last two rows.
) numbers. This will always be the
case, since the b- or g-matrix is positive definite, and this
property provides a solid hint as to the style of a given matrix
output. (Columns of off-diagonal elements may or may not contain
negatives). In the ‘row-first’ cases columns 0, 2 and 5 contain the
matrix diagonals. The factors of two in the columns representing
off-diagonal matrix elements is apparent when comparing the
b-matrices. Finally, one can see how the b=1000 information
translates into the b-matrix file by comparing the last two rows.
Note
This is discussed more below, but current recommendations
for using AFNI DT-calculating functions (e.g., 3dDWItoDT
and 3dDWUncert) is to make AFNI-style b-matrices.
We like the b-matrix format because we can use all of the rows when inputting into
3dDWItoDTor3dDWUncertwith the-bmatrix_FULL *option; gradient vector-based options would want one less row, just assuming that the 0th volume in the set is b=0, which might not be the case.We like having DW scaling in the matrix info (the b-value), so that we preserve real physical units in the tensor estimates. When using
3dDWItoDTor3dDWUncert, one should probably also use the-scale_out_1000switch to have nice numbers, which are then interpreted as instead of the default ; thus, the
number part for average healthy adult parenchyma would be
“0.7” (in units of )
rather than “0.0007” (in units of ), which might be more annoying for
bookkeeping/calculations.
instead of the default ; thus, the
number part for average healthy adult parenchyma would be
“0.7” (in units of )
rather than “0.0007” (in units of ), which might be more annoying for
bookkeeping/calculations.
7.2.2. Operations¶
Note the name of the function, 1dDW_Grad_o_Mat++, which is now the
recommended processor for gradient/matrix things in AFNI. It
supercedes the older, clunkier 1dDW_Grad_o_Mat. The newer
1dDW_Grad_o_Mat++ has clearer syntax, better defaults and promotes
world peace (in its own small way).
Gradient and matrix information¶
The relevant formats described above can be converted among each other using
1dDW_Grad_o_Mat++. The formats of inputs and outputs are described by the option used, as follows:input/option
style description
example program
-{in,out}_row_vec
row gradients
dcm2niixoutput,TORTOISEinput-{in,out}_col_vec
column gradients
basic input to
3dDWItoDT(not preferred one, tho’)-{in,out}_col_matA
row-first g- or b-matrices (user can choose scaling)
alt. input to
3dDWItoDT(preferred!); (some, maybe)TORTOISEoutput-{in,out}_col_matT
diagonal-first g- or b-matrices
(some/typical)
TORTOISEoutputAdditionally, the file of b-values may be input after the
-in_bvals *option. This might be requisite if converting gradients to b-matrices, for instance (but be sure not to scale up an already-scaled set of vectors/matrices!). One can input either a row- or column-oriented file here;1dDW_Grad_o_Mat++will know what to do with either one (because it will be 1-by-something or something-by-1). When outputting a separate file of b-values, one does have to specify either row or column, using:-out_row_bval_sep *or-out_col_bval_sep *, respectively.The b-values can also be used to define which associated gradient/matrix entries refer to reference images and which to DWIs; if not input, the program will estimate this based on the magnitudes of the gradients– those with essentially zero magnitude are treated as reference markers, and the rest are treated as DWI markers. In general now, the distinction between reference and DW-scaled gradients is not very important: we no longer average reference volumes by default, and it probably shouldn’t be done.
In rare cases, one might want to include a column of b-values in the output gradient/matrix file. One example of this is with DSI-Studio for HARDI fitting. One can enact this behavior using the
-out_col_bvalswitch. The first column of the text file will contain the b-values (assuming you either input b-matrices or used-in_bvals *). This option only applies to columnar output.In contrast to the older
1dDW_Grad_o_Mat, the newer1dDW_Grad_o_Mat++does not try to average b=0 files or to remove the top row of reference volumes from the top of the gradient/matrix files. Nowadays, if one inputs a file with N reference and M DW images, the output would have the gradients/matrices of all. One major reason for
preferring using the AFNI-style b-matrix as the format of
choice is because the full set of values are used via
the -bmatrix_FULL *option in3dDWItoDT,3dDWUncert, etc. (as opposed to ones if using grads or a
difference b-matrix option, for historical reasons).
ones if using grads or a
difference b-matrix option, for historical reasons).
Simultaneous averaging of datasets¶
This is not performed in ``1dDW_Grad_o_Mat++``. We no longer recommend doing this, based on the way tensor fitting is peformed.
How to check about gradient flipping?¶
The discussion of this specific topic has been moved to its own page, @GradFlipTest: checking on gradient flips. Please see there for the mathematical description of gradient flipping and tractographic images of its consequences, as well as the best way to investigate the phenomenon.
(The short answer is, “Use @GradFlipTest.”)
Example 1dDW_Grad_o_Mat++ commands¶
Consider a case where dcm2niix has been used to convert data from
a DWI acquisition, resulting in: a NIFTI file called ALL.nii.gz; a
row gradient file called ALL.bvec (unweighted, unit magnitudes);
and a (row) b-value file called ALL.bval. Let’s say that the
acquisition aquired: 4 b=0 reference images; then 30 DW images with
b=1000. Then:
The following produces a gradient file with 3 columns and 34 rows (unscaled, gradient vectors):
1dDW_Grad_o_Mat++ \ -in_row_vec ALL.bvec \ -out_col_vec dwi_bvec.dat
The following flips the y-component of the input DW gradients and produces a row-first b-matrix (i.e., elements scaled by DW value) file with 6 columns and 34 rows:
1dDW_Grad_o_Mat++ \ -in_row_vec ALL.bvec \ -in_bvals ALL.bval \ -out_col_matA dwi_matA.dat -flip_y
An example of including
@GradFlipTest's guess at an appropriate gradient flip in a pipeline with1dDW_Grad_o_Mat++is provided in “Combining with 1dDW_Grad_o_Mat++ (or fat_proc functions)”.But be sure to also read “Caveats with @GradFlipTest” in order to appreciate the importance of still checking
@GradFlipTestresults by eye yourself (-> something that the function’s output assists with, anyways).Sometimes, to deal with odd sequence protocol necessities, a single DW scaling is stored for each b-value and the gradients themselves are scaled to less than unity to reflect having a lower, applied weighting. Weird. But we can deal with this– the following example would combine the b-values and gradients, and then output gradient-magnitude (column) vector grads and the effective b-values separately:
1dDW_Grad_o_Mat++ \ -in_row_vec ALL.bvec \ -in_bvals ALL.bval \ -out_col_vec dwi_gvec.dat \ -out_col_bval_sep dwi_bval.dat \ -unit_mag_out
The following first selects only some of the gradient and associated b-values (for example, if motion had occured). Of the original 34 volumes, this would select
 gradients, and similar subbrick selection would have to be
applied to the set of DWI volumes:
gradients, and similar subbrick selection would have to be
applied to the set of DWI volumes:1dDW_Grad_o_Mat++ \ -in_row_vec ALL.bvec'[0..3,8,12..$]' \ -in_bvals ALL.bval'[0..3,8,12..$]' \ -out_col_matA dwi_matA_sel.dat 3dcalc \ -a ALL.nii'[0..3,8,12..$]' \ -expr 'a' \ -prefix ALL_sel.nii
Note
Subset selection works similarly as in other AFNI programs, both for datasets and the row/column files. For row text files, one uses square-brackets ‘[A..B]’ to select the gradients A to B. For column text files, one would do the same using curly brackets ‘{A..B}’.
