12.9.1. Introducing Cluster Explorer¶
Too Much Information. [1]¶
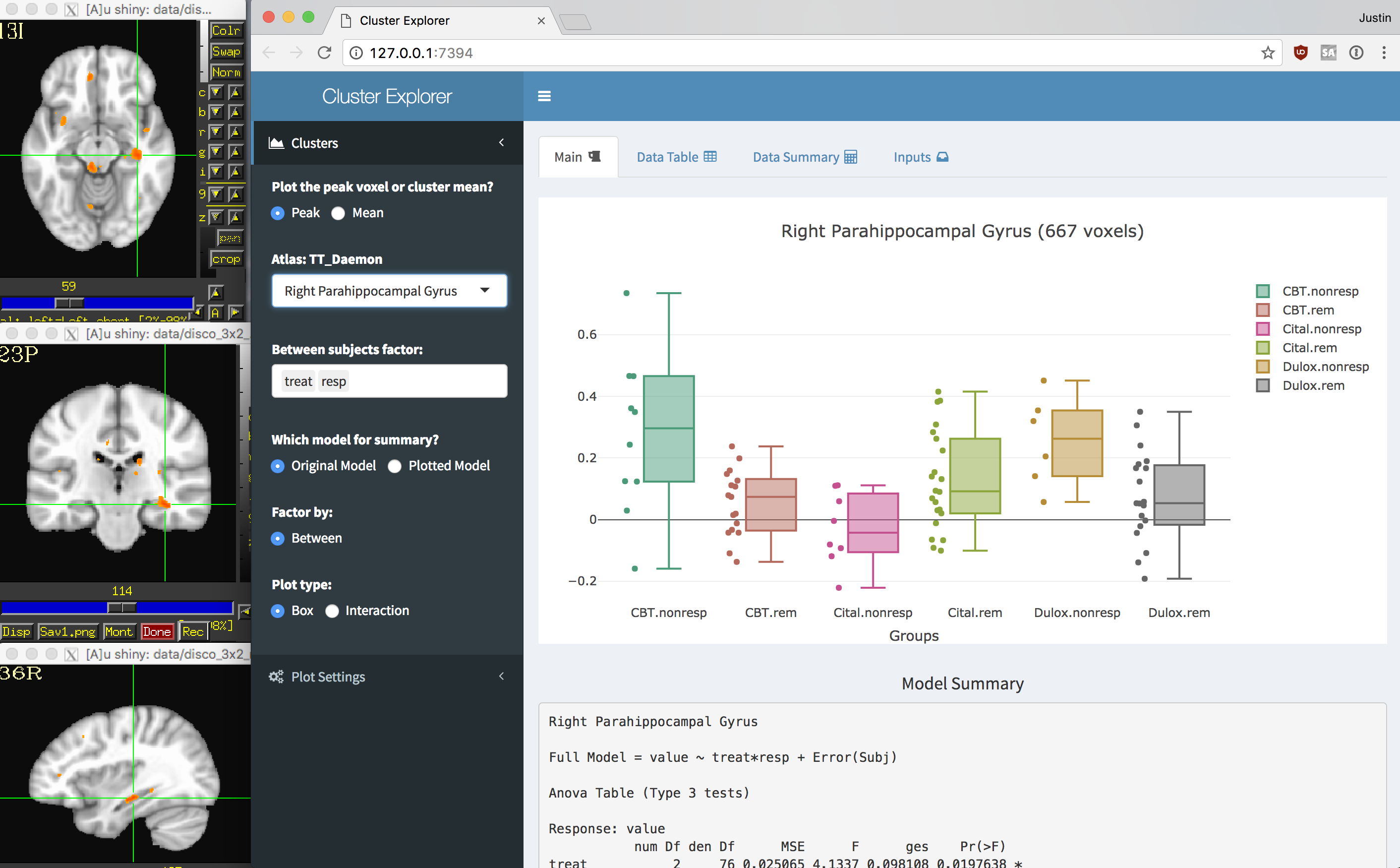
Cluster Explorer is a set of scripts that will allow you to explore your data after you have run some group level analysis. This may hopefully save you some time in preparing your data for figures, publications, and sharing. It automates a few data wrangling steps that enable you to explore your subject data at the cluster level. The end result is a shiny app that you can view in your web browser linked to a afni instance that displays your thresholded statistics dataset and clusters. You can learn more about shiny apps here.
The basic functions performed are:
Collect all of the input datasets.
Threshold and clusterize the statistics dataset.
Look up atlas locations for each cluster.
For each cluster, extract the data from the all of the input datasets.
Extract the model information from the statistics dataset.
Label all clusters for all subjects and merge with the model information.
Create a shiny app that you can share to interactively explore and plot your data.
The Cluster Explorer includes:
ClustExp_HistTable.py@ClustExp_CatLabClustExp_StatParse.py@ClustExp_run_shiny
Ready, ready, ready, ready, ready to run. [2]¶
- Make sure AFNI and R are installed and configured correctly.
Run
@afni_R_package_install -shinyto install necessary R libraries.
What You Need. [3]¶
It helps to be fairly organized… Although not necessary, it is a bit easier if all of your analyses and input datasets are on the same file system. At minimum you need to know where everything is now and where it was when the analysis was run.
You will need (more specifics below):
An output dataset from
3dttest++or3dMVM.3dLMEsupport coming soon.- All of your individual subject datasets.
At least the datasets that went into the analysis, but you can have more.
- A table with your subject ids and current paths to the datasets in a table.
Again, you can have more than what was in the analysis.
- The master template to which the input datasets were aligned.
This will serve as an underlay for viewing results with the shiny app.
Go with the Flow. [4]¶
@ClustExp_CatLabwill collect the input datasets into one big dataset.ClustExp_StatParse.pywill extract cluster-wise subject level data, organize everything and create a shiny app.@ClustExp_run_shinywill launch afni and your browser to view the results.
Flow chart coming soon.
12.9.2. Scripts¶
ClustExp_HistTable.py¶
This script will parse the history from the resulting dataset of 3dttest++
or 3dMVM. (it should work with 3dLME but it has not yet been tested).
This may fail if the dataset has been modified in any way that strips the
information from the history.
The output from this script will be a table (.csv) containing with information
parsed from the statistics dataset history. This may include subject ID, any
group or other variables, and input datasets file names.
Although not necessary, this script may help you organize your data or remember
what you did. You can use this script to help make the table
for @ClustExp_CatLab.
ClustExp_HistTable.py -StatDSET My_ANOVA.nii.gz -prefix My_Sharona
For 3dttest++ the output table will look something like:
Subj |
Group |
InputFile |
subj0046 |
patient |
./subj.0046.nii.gz |
subj0049 |
patient |
./subj.0049.nii.gz |
subj0076 |
patient |
./subj.0076.nii.gz |
subj0082 |
control |
./subj.0082.nii.gz |
subj0131 |
control |
./subj.0131.nii.gz |
subj0173 |
control |
./subj.0173.nii.gz |
For 3dMVM it may look like:
Subj |
treatment |
response |
InputFile |
subj0060 |
CBT |
nonresp |
subj.0060.nii.gz |
subj0082 |
CBT |
nonresp |
subj.0082.nii.gz |
subj0049 |
CBT |
remit |
subj.0049.nii.gz |
subj0076 |
CBT |
remit |
subj.0076.nii.gz |
subj0213 |
Drug |
nonresp |
subj.0213.nii.gz |
subj0231 |
Drug |
nonresp |
subj.0231.nii.gz |
subj0061 |
Drug |
remit |
subj.0061.nii.gz |
subj0075 |
Drug |
remit |
subj.0075.nii.gz |
@ClustExp_CatLab¶
This is a helper script to concatenate all of your input
datasets into one long dataset with each subbrik labeled with a subject ID.
The output dataset from this script serve as the -SubjDSET input
to ClustExp_StatParse.py
@ClustExp_CatLab -input All_My_Subj.csv -prefix All_My_Subj.nii.gz
The input table should have no header, and can be comma, tab, or space separated. Only ONE subbrik per row.
All_My_Subj.csv should contain something like this:
subj01 |
/MyPath/study/subj01.nii.gz[0] |
subj02 |
/MyPath/study/subj02.nii.gz[0] |
subj03 |
/MyPath/study/subj03.nii.gz[0] |
For a within subjects design it may look like this:
subj01 |
/MyPath/study/subj01.nii.gz[Task1#0_Coef] |
subj01 |
/MyPath/study/subj01.nii.gz[Task2#0_Coef] |
subj02 |
/MyPath/study/subj02.nii.gz[Task1#0_Coef] |
subj02 |
/MyPath/study/subj03.nii.gz[Task2#0_Coef] |
subj03 |
/MyPath/study/subj03.nii.gz[Task1#0_Coef] |
subj03 |
/MyPath/study/subj03.nii.gz[Task2#0_Coef] |
ClustExp_StatParse.py¶
Lots of stuff here, so check out the help: ClustExp_StatParse.py -h
Minimum requirements include:
ClustExp_StatParse.py \
-StatDSET My_ANOVA.nii.gz \
-MeanBrik 3 \
-ThreshBrik 3 \
-SubjDSET All_My_Subj.nii.gz \
-SubjTable My_Sharona.csv \
-master ~/abin/MNI152_T1_2009c+tlrc
The -StatDSET argument should specify an output from 3dttest++
or 3dMVM.
For 3dttest++, the -MeanBrik and -ThreshBrik should be an integer
specifying the _mean and _Tstat subbriks. e.g. -MeanBrik 0 -ThreshBrik 1.
If the -covariates argument was used, this script will output an error and
suggest that you use the -NoShiny argument.
For 3dMVM, the -MeanBrik and -ThreshBrik should be the same integer
matching the subbrik for the F stat of your main model. Not a GLT or GLF.
This is usually the last subbrik. e.g. -MeanBrik 3 -ThreshBrik 3.
The -SubjDSET is the output from @ClustExp_CatLab.
The -SubjTable is similar to the input table to @ClustExp_CatLab, but
it needs a 3rd column that contains the location of the input datasets as was
specified original script. This information can be retrieved
using ClustExp_HistTable.py. This is needed to merge the extracted data
with the group and variable information from the history of your statistics
dataset. If the input data is in the same location now as it was when the
analysis was run, the 2nd and 3rd columns would be identical. No headers
are allowed.
For a within subjects design it may look like this:
subj01 |
/MyPath/subj01.nii.gz[Task1#0_Coef] |
./data/subj01.nii.gz[Task1#0_Coef] |
subj01 |
/MyPath/subj01.nii.gz[Task2#0_Coef] |
./data/subj01.nii.gz[Task2#0_Coef] |
subj02 |
/MyPath/subj02.nii.gz[Task1#0_Coef] |
./data/subj02.nii.gz[Task1#0_Coef] |
subj02 |
/MyPath/subj03.nii.gz[Task2#0_Coef] |
./data/subj03.nii.gz[Task2#0_Coef] |
subj03 |
/MyPath/subj03.nii.gz[Task1#0_Coef] |
./data/subj03.nii.gz[Task1#0_Coef] |
subj03 |
/MyPath/subj03.nii.gz[Task2#0_Coef] |
./data/subj03.nii.gz[Task2#0_Coef] |
The -master argument should point to the dataset that was used in
preprocessing. This is required as an underlay for the shiny app and for
verification of matching spaces. Later, I may remove this requirement if used
with the -NoShiny argument. Also later, I will add an automatic lookup
for the built in afni templates.
@ClustExp_run_shiny¶
This is an easy one. It takes just one argument, the path to the output folder
from ClustExp_StatParse.py.
@ClustExp_run_shiny My_ANOVA_ClustExp_shiny
It will launch afni and your default browser. afni will load
the -master as the underlay and a thresholded version of
your -StatDSET as the overlay. The browser will launch a shiny app
with the extracted data to explore.
Footnotes
